Se você chegou até aqui, as chances são de que você ouviu o burburinho em torno do Docker e como ele deve mudar a forma como fazemos deploy de aplicações.
De acordo com o site oficial, Docker é…
…uma plataforma para desenvolvedores e sysadmins desenvolverem, enviarem e executarem aplicações. Docker permite que você monte aplicações rapidamente a partir de componentes e elimina o atrito que pode surgir ao enviar código. Docker permite que você teste e faça deploy do seu código em produção o mais rápido possível.
Não estou aqui para vender nada; aparentemente há muitas pessoas fazendo isso já. Em vez disso, vou documentar minhas experiências tentando “Dockerizar” uma simples aplicação Rails e mostrar algumas coisas que aprendi ao longo do caminho.
A Aplicação
Há alguns meses atrás eu construí o TeXBin, uma
aplicação Rails simples onde você pode postar um arquivo .tex e obter uma URL para sua
versão em PDF. O código estava parado no meu laptop sem uso, então por que não
usá-lo como cobaia na minha primeira tentativa de usar Docker? :-)
A stack proposta é composta por três componentes: a aplicação em si, uma instância MongoDB, e um servidor Nginx para servir o conteúdo estático e atuar como proxy reverso para a aplicação.
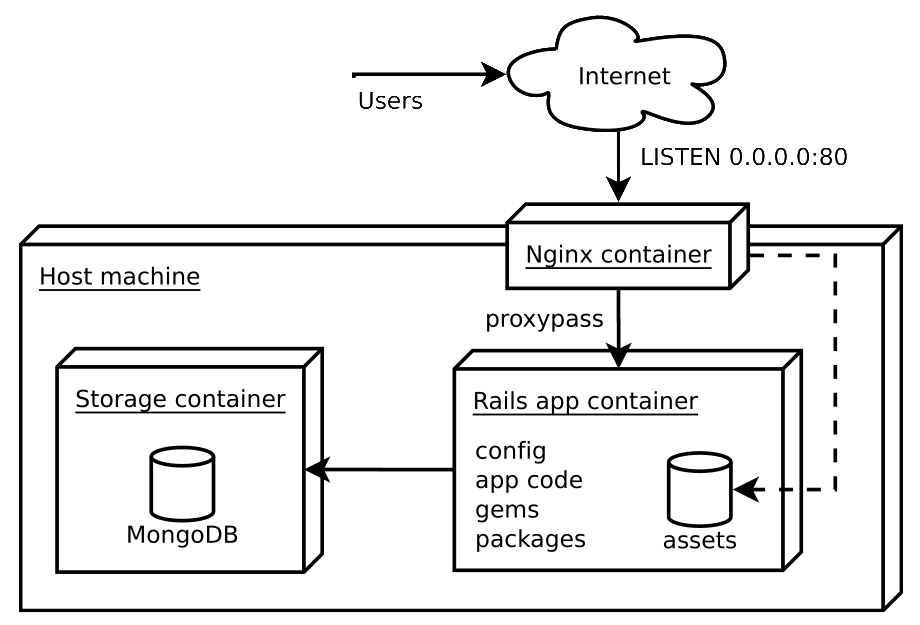
Arquitetura.
WTF é um container?
Docker é construído em cima de recursos do kernel Linux, como cgroups e
namespaces, e fornece uma maneira de criar espaços de trabalho leves – ou
containers – que executam processos de forma isolada.
Ao usar containers, recursos podem ser isolados, serviços restritos e processos provisionados para ter uma visão privada do sistema operacional com seu próprio espaço de ID de processo, estrutura de sistema de arquivos e interfaces de rede. Vários containers podem compartilhar o mesmo kernel, mas cada container pode ser restringido a usar apenas uma quantidade definida de recursos como CPU, memória e I/O.
Então, resumindo, você obtém quase todos os benefícios da virtualização com praticamente nenhum overhead de execução que vem com ela.
Por que não colocar tudo dentro do mesmo container?
Você obtém vários benefícios ao expor os diferentes componentes da sua aplicação como containers diferentes. Só para deixar claro, por componente eu quero dizer algum serviço que se liga a uma porta TCP.
Em particular, ter containers diferentes para componentes diferentes nos dá liberdade para mover as peças ou adicionar novas peças conforme acharmos adequado, como:
- impor diferentes limites de uso (compartilhamentos de CPU e limites de memória) para o banco de dados, a aplicação e o webserver
- mudar de uma simples instância MongoDB para um replica set composto por vários containers em vários hosts
- iniciar dois ou mais containers de aplicação para que você possa realizar blue-green deployments, melhorar a concorrência e uso de recursos, etc
Em outras palavras: é uma boa ideia manter as partes móveis, bem, móveis.
O Dockerfile
Containers são criados a partir de imagens, então primeiro precisamos criar uma imagem com o código da aplicação e todos os pacotes de software necessários.
Em vez de fazer as coisas manualmente, Docker pode construir imagens automaticamente ao
ler as instruções de um Dockerfile, que é um arquivo de texto que contém
todos os comandos que você normalmente executaria manualmente para construir uma
imagem Docker.
Este é o Dockerfile da aplicação:
|
|
Informações sobre os comandos individuais podem ser obtidas aqui.
Dica: Diga Adeus ao RVM
Por que você precisa do RVM se a aplicação vai viver dentro de um ambiente controlado e isolado?
A única razão para querer fazer isso é porque você precisa instalar uma versão específica do Ruby que você não consegue encontrar através dos gerenciadores de pacotes tradicionais do SO. Se esse é o caso, você estará melhor instalando a versão do Ruby que você deseja a partir do código-fonte.
Usar RVM de dentro de um container Docker não é uma experiência agradável; todo
comando deve rodar dentro de uma sessão shell de login e você terá problemas usando
CMD junto com ENTRYPOINT.
Dica: Otimize para o Build Cache
Docker armazena imagens intermediárias após executar com sucesso cada comando no
Dockerfile. Esse é um ótimo recurso; se algum passo falhar ao longo do caminho, você
pode corrigir o problema e o próximo build vai reutilizar o cache construído até aquele
último comando bem-sucedido.
Instruções como ADD não são amigáveis ao cache, no entanto. É por isso que é uma boa
prática apenas adicionar (ADD) coisas o mais tarde possível no Dockerfile, já que qualquer
mudança nos arquivos – ou seus metadados – vai invalidar o cache de build para
todas as instruções subsequentes.
O que nos leva a…
Dica: Não Esqueça o .dockerignore
Um passo realmente importante é evitar adicionar (ADD) arquivos irrelevantes ao
container, como README, fig.yml, .git/, logs/, tmp/, e outros.
Se você está familiarizado com .gitignore, a ideia é a mesma: apenas crie um
arquivo .dockerignore e coloque lá os padrões que você quer ignorar. Isso vai
ajudar a manter a imagem pequena e o build rápido ao diminuir a chance de invalidação
do cache.
Testando as Imagens
Para executar a aplicação, primeiro precisaremos de um container que expõe um único servidor MongoDB:
|
|
Então você tem que construir a imagem da aplicação e iniciar um novo container:
|
|
Aprender como linking de containers e volumes funcionam é essencial se você quer entender como “conectar” containers.
Nota: O projeto também inclui um Dockerfile para o
container Nginx
que não vou mostrar aqui porque não traz nada novo para a discussão.
Agora docker ps deve exibir dois containers rodando. Se tudo estiver
funcionando, você deve conseguir acessar a aplicação em
http://localhost:3000. Para ver os logs, execute docker logs texbin_app_1.
Captura de tela.
Docker em Desenvolvimento
Acontece que é muito fácil automatizar esses últimos passos com Fig:
|
|
Então, execute fig up no terminal para construir as imagens, iniciar os
containers e vinculá-los.
A única diferença entre isso e os comandos que executamos manualmente antes é
que agora estamos montando o diretório atual do host no diretório /texbin/app do
container para que possamos ver nossas alterações na aplicação em tempo real.
Tente mudar algum template .html.erb e atualizar o navegador.
Definindo Novos Ambientes
O objetivo é executar a mesma aplicação em produção, mas com uma configuração diferente, certo? Uma maneira simples de – mais ou menos – resolver isso é criar outra imagem, baseada na anterior, que muda a configuração necessária:
|
|
Se você conhece uma maneira melhor de fazer isso, por favor me avise nos comentários.
Indo para Produção
A primeira coisa a fazer é enviar suas imagens para o servidor. Há várias maneiras de fazer isso: o registry público, um registry privado hospedado, git, etc. Uma vez que as imagens estejam construídas, basta repetir o procedimento que fizemos antes e você está pronto.
Mas isso não é tudo. Como você provavelmente sabe, fazer deploy de uma aplicação envolve muito mais do que apenas mover coisas para alguns servidores remotos. Isso significa que você ainda terá que se preocupar com coisas como automação de deployment, monitoramento (nos níveis de host e container), logging, migrações de dados e backup, etc.
Conclusão
Estou feliz por ter dedicado tempo para olhar o Docker. Apesar de sua pouca idade, é uma peça de tecnologia muito impressionante em rápida evolução com muito potencial para mudar radicalmente o cenário DevOps nos próximos anos.
No entanto, Docker resolve apenas uma variável de uma enorme equação. Você ainda terá que cuidar de coisas chatas como monitoramento, e imagino que seja bastante difícil – para não dizer impossível – usar Docker em produção sem alguma camada de automação em cima dele.
Além disso, recursos como linking de containers são um tanto limitados e provavelmente veremos melhorias substanciais em versões futuras. Então fique ligado!