No último ano, a Descomplica caminhou em direção a uma arquitetura mais orientada a serviços para seus componentes principais (autenticação, busca, etc) e temos usado Elastic Beanstalk desde o início para orquestrar o deployment desses serviços na AWS.
Foi uma boa decisão na época. Em geral, o Elastic Beanstalk funciona bem e tem uma curva de aprendizado muito suave; não demorou muito para que todos os times começassem a usá-lo em seus projetos.
Avançando alguns meses, tudo estava legal e bom. Nossos problemas antigos foram resolvidos, mas - como você deve ter imaginado - tínhamos novos para nos preocupar.
Problemas de Custo
No Elastic Beanstalk, cada instância EC2 executa exatamente um container de aplicação.1 Isso significa que, se você seguir as melhores práticas de confiabilidade, você terá duas ou mais instâncias (distribuídas em múltiplas zonas de disponibilidade) para cada aplicação. Você pode precisar de ainda mais instâncias se tiver outros ambientes além do de produção, i.e. staging.
De qualquer forma, você acabará tendo múltiplas instâncias dedicadas por serviço que, dependendo da sua carga de trabalho, ficarão lá sem fazer nada a maior parte do tempo.
Precisávamos encontrar uma maneira de usar nossos recursos computacionais disponíveis de forma mais inteligente.
O Vencedor
Depois de procurar alternativas ao ECS, o Kubernetes pareceu ser a escolha certa para nós.
Kubernetes é uma ferramenta de orquestração de containers que se baseia em 15 anos de experiência executando cargas de trabalho de produção no Google, combinada com ideias e práticas das melhores da comunidade.
Embora Kubernetes seja um projeto rico em recursos, alguns recursos principais chamaram nossa atenção: namespaces, rollouts e rollbacks automatizados, service discovery via DNS, escalonamento automatizado de containers baseado em uso de recursos, e, é claro, a promessa de um sistema auto-regenerativo.
Kubernetes é um tanto opinativo sobre como os containers devem ser organizados e conectados em rede, mas isso não deve ser um problema se seu serviço segue as práticas do Twelve-Factor.
Nosso Caminho para Produção

Gráfico de atividade do projeto.
Para garantir que Kubernetes era uma opção viável para nós, a primeira coisa que fizemos foi realizar alguns testes de confiabilidade para ter certeza de que poderia lidar com modos de falha como nós morrendo, daemons Kubelet/Proxy/Docker mortos e interrupções de zona de disponibilidade.
É impossível antecipar todas as maneiras como as coisas podem dar errado, mas no final, ficamos muito impressionados com como o Kubernetes conseguiu lidar com essas falhas.
Naquela época, usávamos kube-up para inicializar nossos clusters de teste. Essa ferramenta, embora tenha servido seu propósito, nem sempre funcionou como esperado; sofreu de vários problemas, como padrões mal escolhidos, timeouts aleatórios que deixavam a stack apenas parcialmente criada, e comportamento inconsistente ao destruir o cluster, causando recursos órfãos a serem deixados para trás.2
Uma vez que concordamos que Kubernetes era o caminho a seguir, precisávamos de uma maneira mais confiável de criar e destruir nossos clusters Kubernetes.
Entre kube-aws
kube-aws é uma ferramenta criada por alguns caras legais da CoreOS. A coisa legal sobre ela é que usa CloudFormation por baixo dos panos, o que nos dá algumas vantagens interessantes.
A primeira vantagem óbvia é que é muito fácil criar e destruir clusters sem deixar nada silenciosamente pendurado.
Outro recurso é que, ao contrário do kube-up, você pode criar um cluster em uma VPC existente, então todos os serviços rodando no Kubernetes têm acesso aos seus recursos AWS existentes - como bancos de dados relacionais - imediatamente.
Na verdade, você pode executar múltiplos clusters ao mesmo tempo na mesma VPC. Isso tem um efeito colateral interessante no qual você pode tratar cada cluster como uma peça imutável de infraestrutura; em vez de modificar um cluster em execução - e arriscar quebrar algo - você simplesmente cria um novo cluster e gradualmente muda o tráfego do antigo para o novo de uma forma que qualquer incidente tenha impacto limitado.
O recurso final e provavelmente o mais útil é que você pode facilmente customizar quase todos os aspectos da configuração de provisionamento do cluster para adequá-lo às suas próprias necessidades. No nosso caso, adicionamos logging em nível de cluster que ingere logs da aplicação no Sumologic, monitoramento de cluster com InfluxDB e Grafana, autorização baseada em ABAC, entre outras coisas.
O Primeiro Ambiente
Depois de resolver o problema de criar e destruir clusters de forma confiável, nos sentimos confiantes para começar a migrar nosso ambiente de staging para o Kubernetes.
Foi fácil o suficiente criar manualmente os manifestos yaml para os primeiros deployments, mas precisávamos de uma maneira automatizada de fazer deploy de novas imagens de aplicação assim que fossem construídas pelo nosso sistema de integração contínua.
Apenas como prova de conceito, rapidamente criamos uma pequena função no AWS Lambda (baseada neste artigo) que automaticamente atualizava o objeto de deployment correspondente sempre que recebia uma notificação de merge na qual os testes passaram.
Esta pequena função Lambda agora evoluiu para um componente importante em nosso pipeline de entrega, orquestrando deployments para outros ambientes também, incluindo produção.
Com isso feito, migrar serviços de staging do Beanstalk para Kubernetes foi bem direto. Primeiro, criamos um registro DNS para cada serviço (cada um inicialmente apontando para o deployment legado no Elastic Beanstalk) e garantimos que todos os serviços se referenciassem via esse DNS. Então, foi apenas uma questão de mudar esses registros DNS para apontar para os correspondentes load balancers gerenciados pelo Kubernetes.
Para garantir que cada parte do pipeline estava funcionando como esperado, passamos algum tempo monitorando todos os deployments de staging procurando bugs e polindo as coisas conforme podíamos.
Mais Testes, Mais Aprendizado
Antes de fazer deploy do nosso primeiro serviço de produção no Kubernetes, fizemos alguns testes de carga para descobrir a configuração ideal para os requisitos de recursos necessários por cada serviço e quantos pods precisávamos para lidar com o tráfego atual.
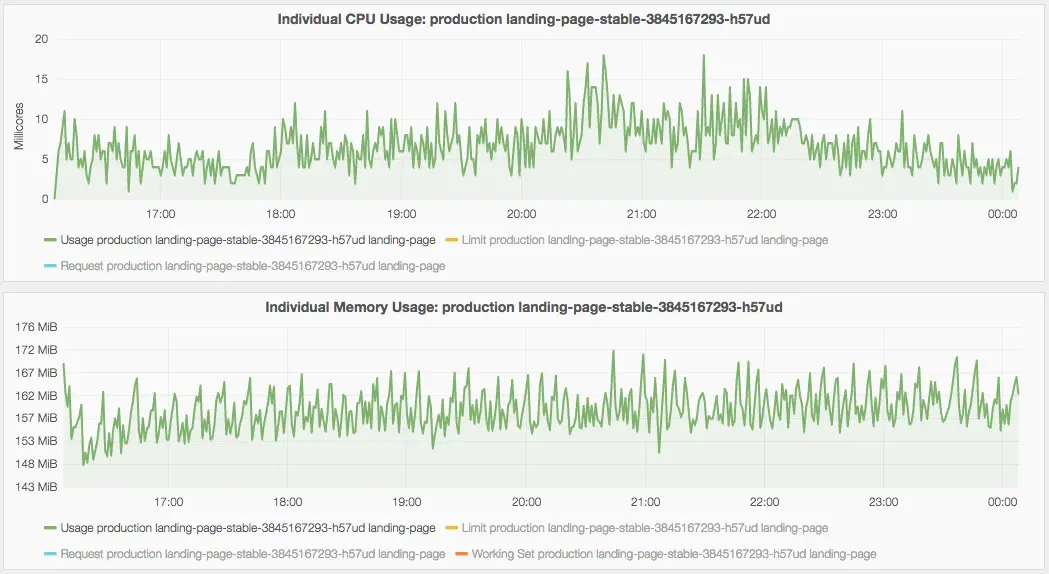
Uso de CPU e memória para um container.
Observar como seus serviços se comportam sob carga e quanto processamento eles precisam é essencial.
Também reserve algum tempo para entender como as classes de QoS funcionam no Kubernetes para que você tenha um controle mais fino sobre quais pods são mortos no caso de pressão de memória. Isso é particularmente importante se você, como nós, compartilha o mesmo cluster para todos os ambientes.
Dica: Habilite Cross-Zone Load Balancing (AWS)
Isso já está corrigido no Kubernetes 1.4, mas por enquanto, se você expor seus serviços através do tipo LoadBalancer, não esqueça de manualmente habilitar cross-zone load balancing para o ELB correspondente; se você não fizer isso, pode notar balanceamento desigual entre seus pods de aplicação se eles estiverem distribuídos em nós de diferentes zonas de disponibilidade.
Dica: Dê Amor ao Namespace kube-system
Se você já experimentou Kubernetes, provavelmente notou que há um namespace kube-system
lá com um monte de coisas nele; faça um favor a si mesmo e reserve algum
tempo para entender o papel de cada uma dessas coisas.
Por exemplo, pegue o DNS add-on; é bastante comum ver pessoas tendo problemas porque esqueceram de adicionar mais pods de DNS para lidar com sua carga de trabalho sempre crescente.
Indo para Produção
Em vez de mudar todo o tráfego de uma vez, como fizemos em staging, pensamos que precisávamos ter uma abordagem mais cuidadosa e usamos política de roteamento ponderado para gradualmente mudar o tráfego para o cluster Kubernetes.
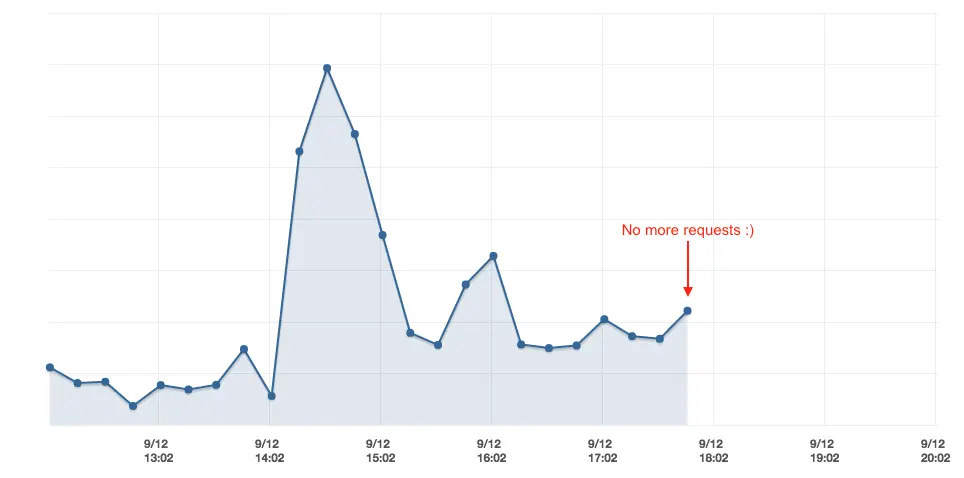
Contagem de requisições recebidas para uma aplicação no Elastic Beanstalk.
Uma vez que notamos que não havia mais requisições chegando aos ambientes Beanstalk legados, fomos em frente e os encerramos.
Atualização (21 de set, 2016): Todos os principais serviços foram migrados para nossa nova plataforma! Estes são os números finais:3
- ~53-63% de redução nos custos mensais
- ~72-82% de redução no número de instâncias
Além da Produção
Kubernetes nos deu o poder de quase sem esforço moldar nosso pipeline de entrega de uma maneira que nunca pensamos ser possível. Um exemplo de tal melhoria é o que chamamos aqui de ambientes de desenvolvimento.
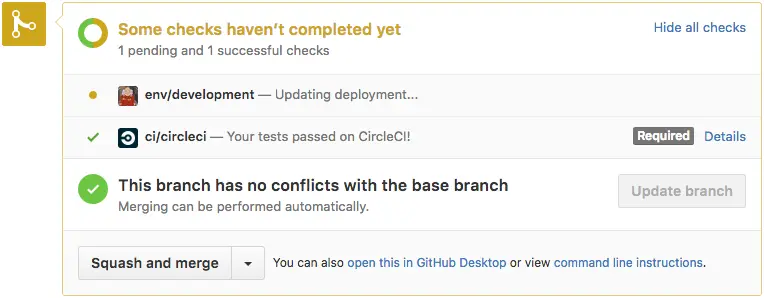
Status de deployment para o ambiente de desenvolvimento de uma aplicação.
Sempre que alguém abre um Pull Request para um de nossos projetos, a função AWS Lambda que mencionei anteriormente cria um ambiente temporário executando as modificações introduzidas pelo PR.
Além disso, sempre que novo código é enviado, esse ambiente é automaticamente atualizado desde que passem nos testes. Finalmente, quando o PR é mergeado (ou fechado), o ambiente é deletado.
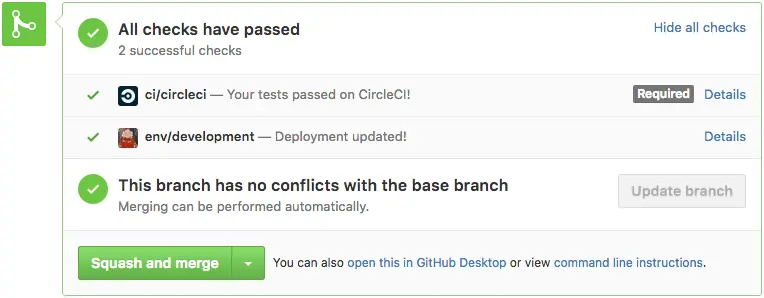
Status do GitHub exibindo que o deployment foi finalizado.
Esse recurso tornou nossas revisões de código mais completas porque os desenvolvedores podem realmente ver as mudanças rodando. Isso é ainda mais útil para mudanças de UX em serviços de front-end; artistas e product owners têm a chance de validar as mudanças e compartilhar seus inputs antes do PR ser mergeado.
Para enviar as notificações de GitHub Status que você vê nessas imagens,
implementamos um pequeno daemon em Go que monitora deployments no nosso
namespace development e reconcilia o status de deployment para cada revisão.
Conclusão
Kubernetes é um software muito complexo que visa resolver um problema muito complexo, então espere passar algum tempo aprendendo como suas muitas peças se encaixam antes de usá-lo em seus projetos.
Kubernetes está pronto para produção, mas evite a tentação de tentar executar tudo nele. Em nossa experiência, Kubernetes não oferece uma solução limpa para vários problemas que você pode enfrentar, como aplicações stateful.
A documentação também não é ótima, mas iniciativas como o Kubernetes Bootcamp e Kubernetes The Hard Way do Kelsey Hightower me dão esperança de que isso não será mais um problema em um futuro próximo.
Sem Kubernetes, não sei como - ou se - poderíamos ter realizado todas as coisas que fizemos em um período tão pequeno de tempo com uma equipe de engenharia tão pequena.4
Esperamos continuar construindo sobre Kubernetes para tornar nossa plataforma de entrega ainda mais dinâmica e incrível!
-
Cada região AWS parece evoluir em um ritmo diferente. No momento em que escrevo, aplicações Beanstalk multi-container e ECS não estavam disponíveis para a região
sa-east-1. Quase todos os nossos usuários vivem no Brasil, então mudar para uma região diferente não era realmente uma opção. ↩︎ -
Há várias iniciativas para criar uma ferramenta melhor para criar e gerenciar clusters Kubernetes, como kops. ↩︎
-
A faixa depende da carga de trabalho. ↩︎
-
A equipe de ops/delivery é na verdade uma equipe de um engenheiro: eu! ↩︎