A proporção “saudável” amplamente aceita, particularmente em empresas com práticas SRE maduras como o Google, é um SRE para cada 10 Engenheiros de Software (SWEs) (uma proporção 1:10). No entanto, essa proporção pode variar significativamente com base nas necessidades específicas de uma organização, tamanho e maturidade de sua automação e ferramentas.
– Gemini
Nos últimos 10+ anos trabalhando como SRE, a maior parte em squads com poucos funcionários em start-ups em estágio avançado, a proporção SRE:SWE estava longe do padrão “ouro” 1:10. Uma proporção mais precisa na minha experiência é 1:30 - 1:40, e neste cenário, dizer que as coisas podem ficar bem ocupadas é um eufemismo.
Trabalhar em ambientes altamente restritos como esses não vem sem seus desafios, tanto culturais quanto técnicos. Para cada tarefa que você escolhe trabalhar, há umas dez outras que você precisa colocar em espera, tudo isso enquanto faz o seu melhor para não se tornar um gargalo para toda a organização.
Mas essa não é a única restrição a que estou acostumado. A outra é eficiência de custos; aqui, terceirizar tudo para ofertas SaaS caras não é uma opção, então geralmente recorremos a auto-hospedagem, ajuste e união de ferramentas open source para nossas necessidades. Fazer deploy de uma nova ferramenta também é algo que não levamos de forma leviana, já que cada nova ferramenta pode arrastar o time para um inferno operacional, então tendemos a apostar em ferramentas chatas/flexíveis em oposição às super-especializadas.
O Problema
Enquanto trabalhava na melhoria da maturidade operacional e de segurança da organização, queríamos revisar e reduzir permissões diretas ao ambiente de produção, e uma possibilidade era usar Terraform, que a equipe de SRE já usava e conhecia. Mas como poderíamos fornecer às outras equipes as mesmas ferramentas que usávamos1 de uma forma que fosse segura, dentro das melhores práticas estabelecidas e, mais importante, não exigisse que a equipe SRE revisasse todos e cada um dos PRs de Terraform?
Aqui está uma lista não exaustiva de coisas que buscávamos:
- Aplicar convenções de nomenclatura consistentes2
- Garantir que recursos tinham as labels corretas para rastreamento adequado de propriedade e custos
- Bloquear operações perigosas (i.e. deleção de database/bucket)
- Garantir práticas recomendadas de durabilidade (i.e. forçar backups para bancos de dados de produção)
- Forçar práticas recomendadas de segurança (i.e. exigir TLS para instâncias de DB)
Ao mesmo tempo, não queríamos sempre bloquear coisas que fugissem do caminho padrão. Alguns desses requisitos foram criados depois que a infraestrutura crítica já estava em vigor, então estes precisavam ser suportados.
Outra razão é que às vezes o time pode ter uma boa razão para criar um bucket exposto publicamente ou desabilitar autenticação para uma instância Redis, etc, então um fluxo de trabalho para aprovar essas mudanças também era necessário.
A solução mais simples (e barata) na época foi codificar essas práticas como políticas OPA e habilitar conftest em nossos pipelines Atlantis. O fluxo de trabalho não é perfeito, mas faz o trabalho.
Com essas políticas em vigor, as equipes podiam ter seus próprios fluxos de trabalho Terraform e aplicar mudanças em produção sem esperar pelo SRE para mudanças que eram consideradas inofensivas, reduzindo profundamente a carga de revisão de PR no time.3
Outras opções que consideramos:
- GCP Organization Policies: Usamos Google Cloud para a maioria das coisas, mas também usamos serviços específicos de outras clouds públicas (AWS, Azure), então uma solução específica de cloud não era uma opção; atrito maior que o desejado em caso de violações de política / cenários de break glass.
- Terraform Cloud + Sentinel: Histórico recente de decisões hostis contra a comunidade; modelo de precificação baseado em recursos sob gerenciamento.
- Spacelift e Env0: Muito caros para o número de usuários e recursos (single sign-on, RBAC, etc) que precisávamos.
Um Exemplo Simples
Tivemos grande sucesso usando GenAI para gerar tanto políticas quanto testes para vários casos, mas para você começar, aqui está uma política que peguei da nossa biblioteca:
|
|
Conforme nossa coleção de políticas cresceu, acabamos com alguns pacotes extras para reutilizar algum comportamento comum, como:
|
|
Linting e Testes
Recomendo usar Regal para evitar erros comuns e ajudá-lo a escrever código Rego mais idiomático:
% regal lint .
3 files linted. No violations found.Também é importante escrever testes para suas políticas para acelerar o ciclo de feedback ao introduzir novas políticas enquanto detecta regressões cedo.
Aqui está um exemplo de suite de testes para aquela política:
|
|
Executando os testes:
% conftest verify --report full
policy/gcp/bucket_force_destroy_tests.rego:
data.gcp_test.test_allow_create_bucket_with_force_destroy: PASS (926.401µs)
data.gcp_test.test_allow_empty_resource_changes: PASS (1.026078ms)
data.gcp_test.test_allow_update_bucket_with_force_destroy: PASS (857.508µs)
data.gcp_test.test_deny_delete_bucket_with_force_destroy: PASS (1.506513ms)
data.gcp_test.test_allow_delete_bucket_without_force_destroy: PASS (1.319212ms)
data.gcp_test.test_allow_delete_other_resource_type: PASS (1.329778ms)
--------------------------------------------------------------------------------
PASS: 6/6O Que Não Funciona Tão Bem
Os pontos a seguir são específicos da integração OPA integrada para Atlantis, que é o que usamos atualmente.
UX para Violações de Política
Se você tem um único conjunto de políticas com algumas dúzias de políticas e um único aprovador, a UX é boa o suficiente, mas conforme sua biblioteca de políticas cresce e você começa a separá-las em diferentes conjuntos de políticas com diferentes proprietários/aprovadores, as mensagens de violação de política podem ficar muito longas e confusas.
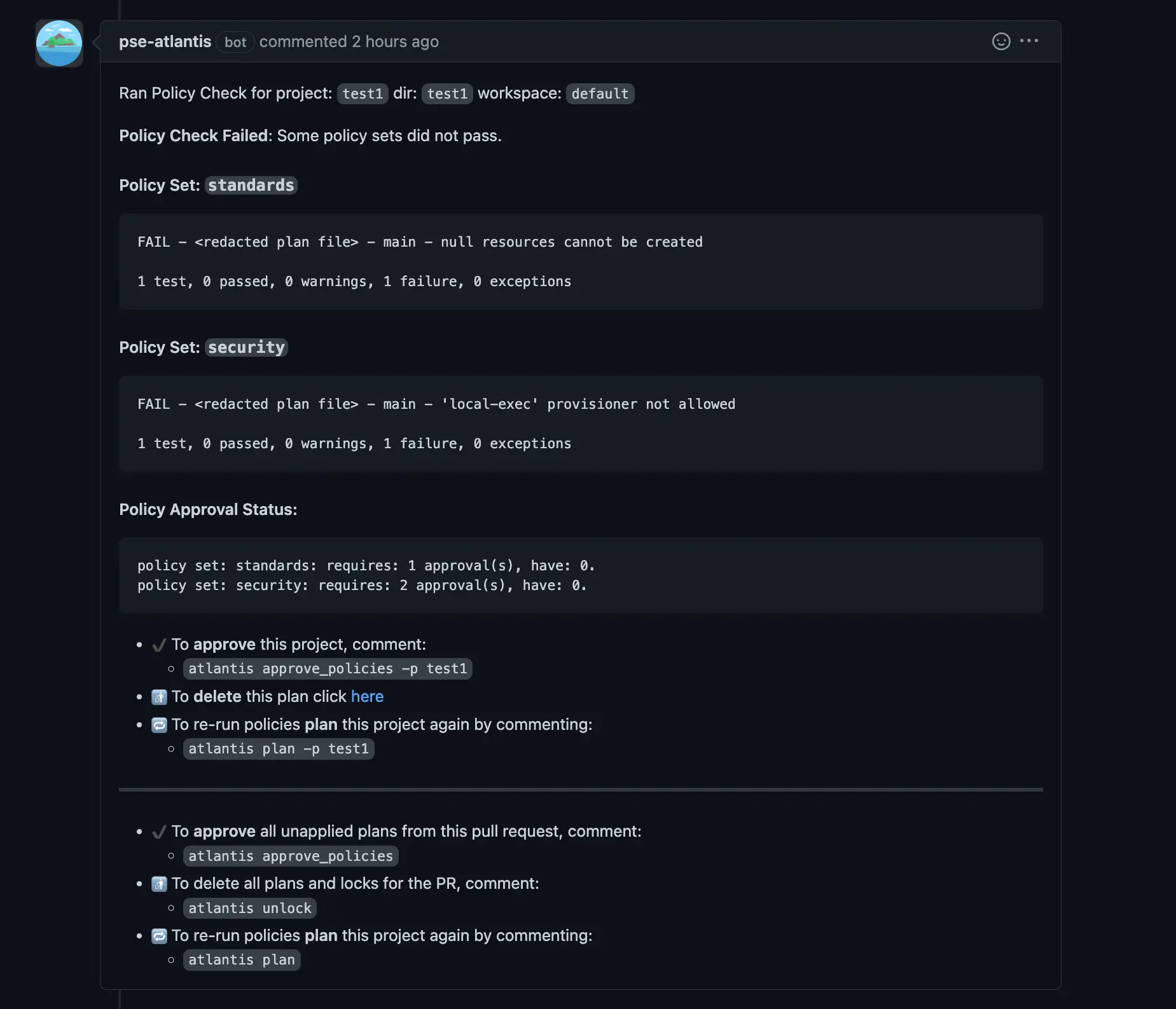
Notificação de violação de política como um comentário do Atlantis.
Por padrão, esta notificação também é enviada mesmo quando nenhuma violação de política é detectada, aumentando o ruído de comentários em seus PRs. Para mitigar isso, você pode experimentar a flag de servidor --quiet-policy-checks.
Fluxo de Trabalho para Gerenciar Conjuntos de Políticas
Conjuntos de políticas são configurados via configuração de repositório do lado do servidor do Atlantis, que é um arquivo de configuração estático:
|
|
É ok começar criando políticas em um único conjunto, mas conforme você cresce, provavelmente precisará atribuir diferentes proprietários para diferentes conjuntos de políticas.
Além disso, dependendo da frequência com que você atualiza suas políticas, você pode querer desacoplar o fluxo de trabalho de atualização de políticas do ciclo de vida do servidor Atlantis. Conftest (e portanto Atlantis) pode buscar políticas de um repositório GitHub, repositório OCI, etc, então use isso a seu favor – mas você precisa ter cuidado para sincronizar mudanças disruptivas (i.e. mudanças na estrutura de diretórios) com a configuração de repositório do lado do servidor do Atlantis.
Sem Suporte Integrado para Notificações de Política
Quando um PR dispara uma ou mais violações de política, tudo que o Atlantis faz é criar um comentário no PR. No nosso caso, quando isso acontece, os próprios usuários escalam para a equipe SRE para revisão ou aprovação, mas isso pode não funcionar para você.
Se você precisa de outras formas de ser notificado sobre violações de política (e.g. via Slack), você precisará implementar isso você mesmo.
Uma maneira poderia ser escrever um pequeno GitHub App que recebe hooks para todos os comentários em um PR, detectando os comentários de violação de política, analisando/encaminhando-os para os proprietários via Slack, e talvez também fornecendo ações diretamente na notificação para aprovação.4
Aprovações de Política vs Sincronizações de Branch
Se você aprovar uma política para um branch que está fora de sincronia com o branch principal, a aprovação da política será “apagada” após o rebase e você terá que aprová-la novamente, mesmo quando nenhum código no PR muda. Isso é particularmente irritante para mudanças que exigem muito vai-e-vem devido a erros de apply.
Se você quiser resolver isso, terá que preparar algo você mesmo.
Novamente, algum tipo de GitHub App que automaticamente re-aprova um PR que já foi aprovado por algum humano desde que o conjunto de políticas violadas e recursos envolvidos não mudem.
API do Atlantis
Uma vez tentei habilitar a API do Atlantis para implementar detecção e correção básica de drift, mas não consegui fazer funcionar. Como os primitivos do Atlantis funcionam em cima de pull requests, mesmo ao usar a API, você precisará fornecer um número de PR válido ao solicitar um plan ou apply, e mesmo assim as coisas não funcionaram como eu esperava.
Recomendações
- Deixe-me repetir: faça lint e escreva testes para suas políticas!
- Adicione algum identificador único para cada erro de política (i.e.
GCP001); isso permitiria que você rastreasse a frequência com que cada política está sendo disparada, e talvez até fornecer uma wiki legal para seus usuários que explique cada política em detalhes, como resolver o problema, etc. - Evite colocar muita coisa no mesmo arquivo; mantenha cada política em um arquivo separado.
- Revise periodicamente suas políticas; verifique se elas estão bloqueando coisas que precisam ser bloqueadas, ou apenas introduzindo ruído sem benefícios reais; remova políticas ruins/inúteis.
- Seja cauteloso ao adotar pacotes de políticas de terceiros, a menos que você tenha uma forma de habilitar ou desabilitar granularmente políticas específicas que não fazem sentido para sua própria situação.
Sobre a parte de revise periodicamente suas políticas: Em uma ocasião, identificamos que uma única policy direcionado a um único resource era responsável por 46% de todos os erros de violação de policy que tivemos nos últimos 90 dias!
Conclusão
Se você me perguntar se acho que este é o fluxo de trabalho dos sonhos para código Terraform, estaria mentindo se dissesse que é. Mas ei, é open source, funciona razoavelmente bem desde que você não queira fazer nada muito maluco, e nos ajudou muito. Até fiz uma contribuição para o projeto há alguns anos.
Se meu empregador tivesse bolsos mais fundos, poderíamos ter ido em outras direções, mas estou feliz que o Atlantis existe. Agora que o projeto foi aceito na CNCF, minhas esperanças estão altas!
Para aqueles que usam Atlantis e se depararam com alguns desses problemas, ficaria feliz em saber como vocês os resolveram!
-
Terraform é uma ótima ferramenta, mas não ideal como ferramenta principal para equipes de desenvolvimento, pois opera em um nível mais baixo. No futuro, podemos explorar ferramentas como Crossplane, onde poderíamos construir APIs baseadas em abstrações que fazem sentido para nossa própria realidade. ↩︎
-
Módulos Terraform são ferramentas importantes para tarefas como essas, permitindo que você ‘codifique’ os padrões da sua organização diretamente como módulos e os reutilize onde necessário. No nosso caso, já tínhamos código gerenciando recursos de cloud diretamente, então migrar tudo para módulos antecipadamente era trabalho demais. Com OPA, poderíamos estancar o sangramento ao menos prevenindo a criação de novos recursos não conformes e começar a obter valor cedo no processo. ↩︎
-
Isso pode funcionar melhor ou pior para sua organização dependendo de vários fatores, como a maturidade da equipe e a restritividade (ou flexibilidade) de suas políticas. Você precisa de revisões periódicas para identificar políticas constantemente quebradas e ajustá-las para um melhor equilíbrio entre ruído e segurança. ↩︎
-
Essa é uma das coisas que não tivemos tempo de polir, sendo uma equipe pequena com muita coisa em nossos pratos. Talvez eu dê uma chance nisso e publique como um projeto open source. ↩︎