Este é um tutorial introdutório que criei para contar aos desenvolvedores de software na Descomplica (onde trabalhei na época) o básico sobre Prometheus.
O Projeto
Este tutorial segue uma abordagem mais prática (com esperançosamente a quantidade certa de teoria!), então fornecemos uma configuração simples do Docker Compose para simplificar a inicialização do projeto.
Você pode baixar o código daqui.
Pré-requisitos
- Docker + Docker Compose
Executando o Código
Execute o seguinte comando para iniciar tudo:
|
|
- Alertmanager: http://localhost:9093
- Grafana: http://localhost:3000 (usuário/senha:
admin) - Prometheus: http://localhost:9090
- Aplicação Node.js de Exemplo: http://localhost:4000
Limpeza
Execute o seguinte comando para parar todos os containers em execução deste projeto:
|
|
Visão Geral do Prometheus
Prometheus é um banco de dados de séries temporais (TSDB) e sistema de monitoramento open source projetado após o Borgmon, a ferramenta de monitoramento criada internamente no Google para coletar métricas de jobs rodando em sua plataforma de orquestração de cluster, Borg.
A imagem a seguir mostra uma visão geral da arquitetura do Prometheus.
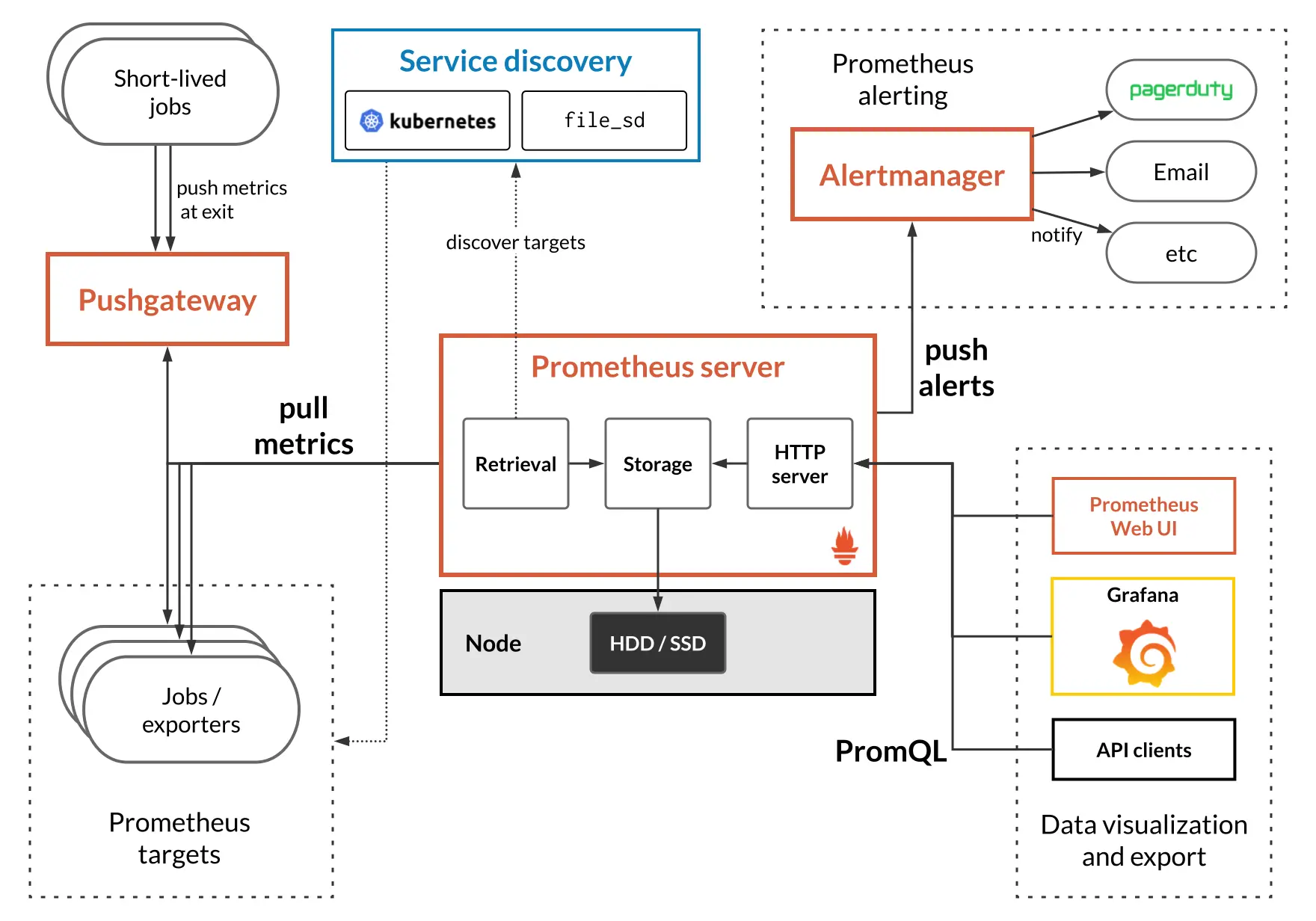
Arquitetura do Prometheus.
No centro temos um servidor Prometheus, que é o componente responsável por coletar e armazenar periodicamente métricas de vários targets (e.g. os serviços dos quais você quer coletar métricas).
A lista de targets pode ser definida estaticamente no arquivo de configuração do Prometheus, ou podemos usar outros meios para descobrir automaticamente esses targets via Service discovery. Por exemplo, se você quer monitorar um serviço que está deployado em instâncias EC2 na AWS, você pode configurar o Prometheus para usar a API AWS EC2 para descobrir quais instâncias estão rodando um serviço particular e então scrape métricas desses servidores; isso é preferível a listar estaticamente os endereços IP para nossa aplicação no arquivo de configuração do Prometheus, que eventualmente ficará fora de sincronia, especialmente em um ambiente dinâmico como um provedor de cloud pública.
O Prometheus também fornece uma Web UI básica para executar consultas nos dados armazenados, bem como integrações com ferramentas de visualização populares, como Grafana.
Push vs Pull
Anteriormente, mencionamos que o servidor Prometheus scrapes (ou faz pull) de métricas de nossas aplicações target.
Isso significa que o Prometheus adotou uma abordagem diferente de outras ferramentas de monitoramento “tradicionais”, como StatsD, nas quais as aplicações fazem push de métricas para o servidor ou agregador de métricas, em vez de ter o servidor de métricas pulling métricas das aplicações.
A consequência desse design é uma melhor separação de responsabilidades; quando a aplicação faz push de métricas para um servidor ou agregador de métricas, ela tem que tomar decisões como: para onde fazer push das métricas; com que frequência fazer push das métricas; a aplicação deve agregar/consolidar quaisquer métricas antes de fazer push delas; entre outras coisas.
Em sistemas de monitoramento baseados em pull como Prometheus, essas decisões desaparecem; por exemplo, não precisamos mais re-deployar nossas aplicações se quisermos mudar a resolução das métricas (quantos pontos de dados coletados por minuto) ou o endpoint do servidor de monitoramento (podemos arquitetar o sistema de monitoramento de uma forma completamente transparente para os desenvolvedores de aplicação).
Quer saber mais? A documentação do Prometheus fornece uma comparação com outras ferramentas no espaço de monitoramento em relação a escopo, modelo de dados e armazenamento.
Agora, se a aplicação não faz push de métricas para o servidor de métricas, como as métricas das aplicações acabam no Prometheus?
Endpoint de Métricas
Aplicações expõem métricas para o Prometheus via um endpoint de métricas. Para ver como
isso funciona, vamos iniciar tudo executando docker-compose up -d se você ainda
não o fez.
Visite http://localhost:3000 para abrir o Grafana e faça login com o usuário e senha padrão
admin. Então, clique no link superior “Home” e selecione o
dashboard “Prometheus 2.0 Stats”.
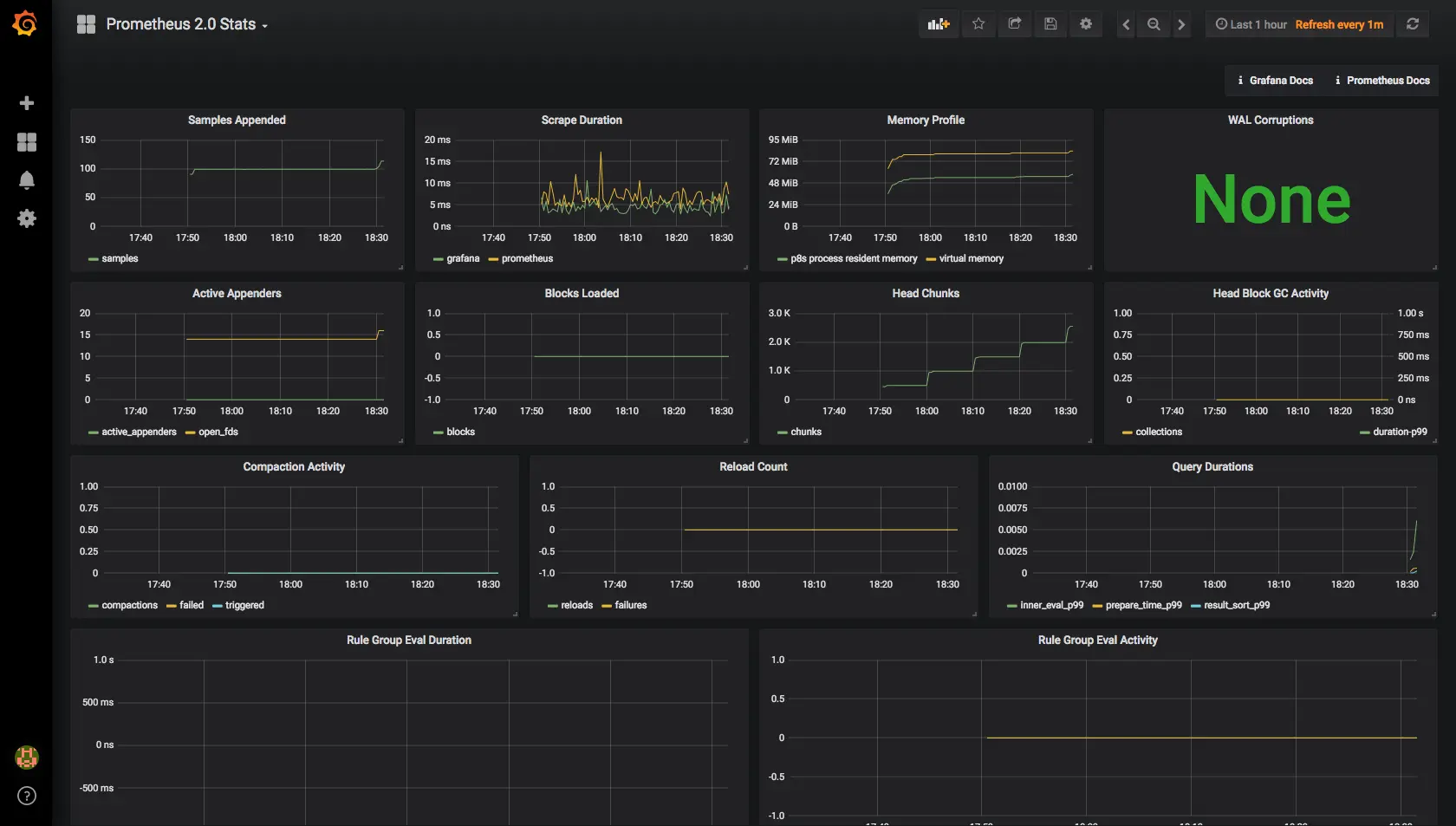
Dashboard Prometheus 2.0 Stats no Grafana.
Sim, o Prometheus está scraping métricas de si mesmo!
Vamos pausar por um momento para entender o que aconteceu. Primeiro, o Grafana já está configurado com uma fonte de dados Prometheus que aponta para o servidor Prometheus local. É assim que o Grafana consegue exibir dados do Prometheus. Além disso, se você olhar o arquivo de configuração do Prometheus, pode ver que listamos o próprio Prometheus como um target.
|
|
Por padrão, o Prometheus obtém métricas via o endpoint /metrics em cada target,
então se você acessar http://localhost:9090/metrics, você deve ver algo como
isso:
# HELP go_gc_duration_seconds A summary of the GC invocation durations.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 5.95e-05
go_gc_duration_seconds{quantile="0.25"} 0.0001589
go_gc_duration_seconds{quantile="0.5"} 0.0002188
go_gc_duration_seconds{quantile="0.75"} 0.0004158
go_gc_duration_seconds{quantile="1"} 0.0090565
go_gc_duration_seconds_sum 0.0331214
go_gc_duration_seconds_count 47
# HELP go_goroutines Number of goroutines that currently exist.
# TYPE go_goroutines gauge
go_goroutines 39
# HELP go_info Information about the Go environment.
# TYPE go_info gauge
go_info{version="go1.10.3"} 1
# HELP go_memstats_alloc_bytes Number of bytes allocated and still in use.
# TYPE go_memstats_alloc_bytes gauge
go_memstats_alloc_bytes 3.7429992e+07
# HELP go_memstats_alloc_bytes_total Total number of bytes allocated, even if freed.
# TYPE go_memstats_alloc_bytes_total counter
go_memstats_alloc_bytes_total 1.37005104e+08
...
Neste trecho sozinho podemos notar algumas coisas interessantes:
- Cada métrica tem uma descrição amigável que explica seu propósito
- Cada métrica pode definir dimensões adicionais, também conhecidas como labels. Por
exemplo, a métrica
go_infotem uma labelversion- Cada série temporal é identificada unicamente por seu nome de métrica e o conjunto de pares label-valor
- Cada métrica é definida como um tipo específico, como
summary,gauge,counter, ehistogram. Mais informações sobre cada tipo de dados podem ser encontradas aqui
Mas como essa resposta baseada em texto se transforma em pontos de dados em um banco de dados de séries temporais?
A melhor maneira de entender isso é executando algumas consultas simples.
Abra a UI do Prometheus em http://localhost:9090/graph, digite
process_resident_memory_bytes no campo de texto e clique em Execute.
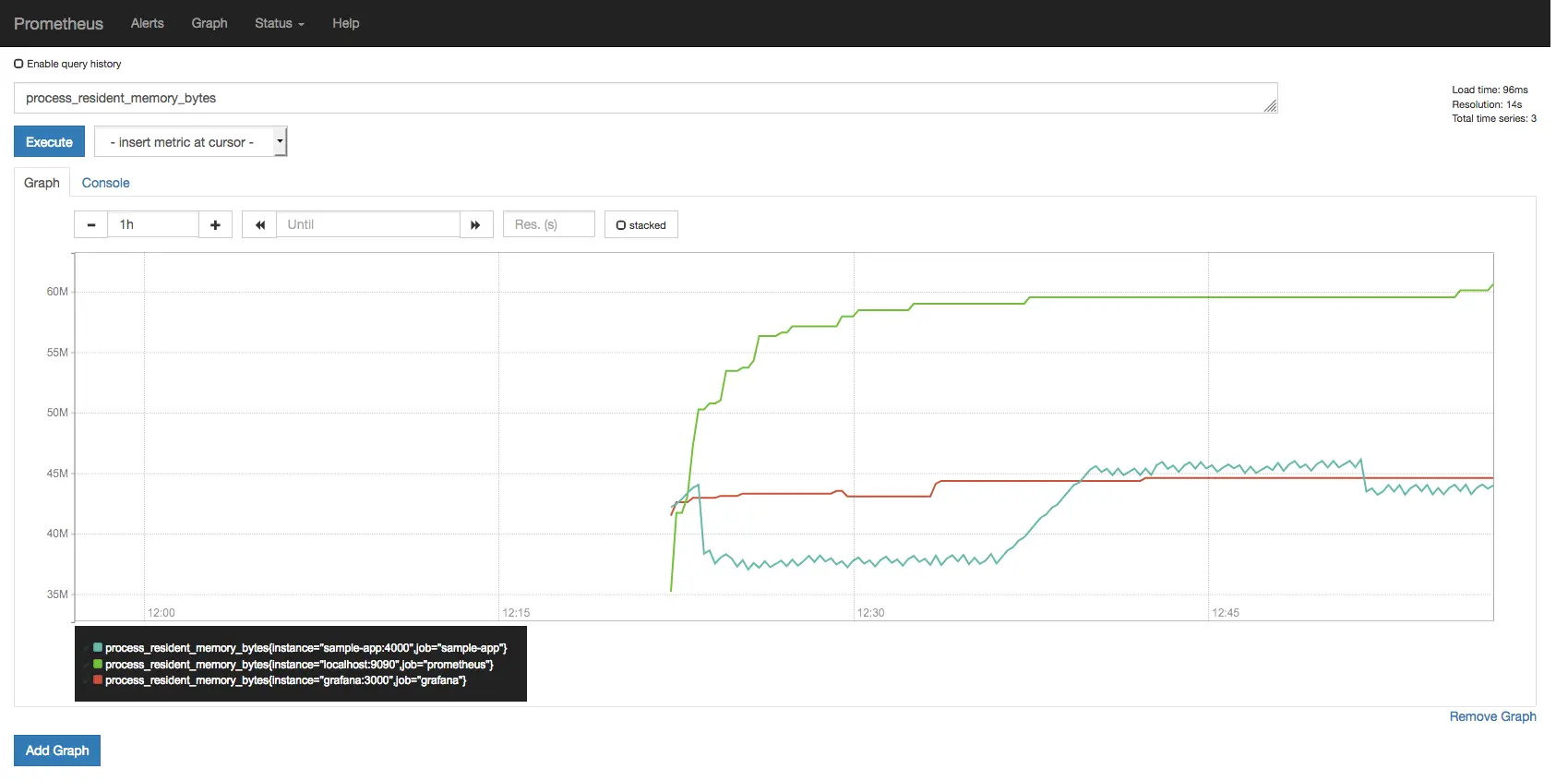
Exemplo de consulta de process_resident_memory_bytes na UI do Prometheus.
Você pode usar os controles do gráfico para dar zoom em uma região específica.
Esta primeira consulta é muito simples já que apenas plota o valor do
gauge process_resident_memory_bytes conforme o tempo passa, e como você deve
ter imaginado, essa consulta exibe o uso de memória residente para cada target,
em bytes.
Como nossa configuração usa um intervalo de scrape de 5 segundos, o Prometheus acessará o
endpoint /metrics de nossos targets a cada 5 segundos para buscar as métricas
atuais e armazenar esses pontos de dados sequencialmente, indexados por timestamp.
|
|
Você pode ver todas as amostras daquela métrica no último minuto consultando
process_resident_memory_bytes{job="grafana"}[1m] (selecione Console na
UI do Prometheus):
| Elemento | Valor |
|---|---|
process_resident_memory_bytes{instance="grafana:3000",job="grafana"} |
40861696@1530461477.44643298816@1530461482.44743778048@1530461487.45144785664@1530461492.44744785664@1530461497.44745043712@1530461502.44845043712@1530461507.4445301760@1530461512.45145301760@1530461517.44845301760@1530461522.44845895680@1530461527.44845895680@1530461532.447 |
Consultas que têm uma duração de intervalo anexada entre colchetes após
o nome da métrica (i.e. <métrica>[<duração>]) retornam o que é chamado de
vetor de intervalo, no qual <duração> especifica quão longe no passado
valores devem ser buscados para cada elemento do vetor de intervalo resultante.
Neste exemplo, o valor para a métrica process_resident_memory_bytes
no timestamp 1530461477.446 era 40861696, e assim por diante.
Nomes de Métricas Duplicados?
Se você inspecionar o conteúdo do endpoint /metrics em todos os nossos targets,
verá que múltiplos targets exportam métricas sob o mesmo nome.
Mas isso não é um problema? Se estamos exportando métricas sob o mesmo nome, como podemos ter certeza de que não estamos misturando métricas entre diferentes aplicações nos mesmos dados de séries temporais?
Considere a métrica anterior, process_resident_memory_bytes: Grafana,
Prometheus e nossa aplicação de exemplo todos exportam uma métrica gauge sob o
mesmo nome. No entanto, você notou no gráfico anterior que de alguma forma conseguimos
obter uma série temporal separada de cada aplicação?
Citando a documentação:
Nos termos do Prometheus, um endpoint que você pode fazer scrape é chamado de instance, geralmente correspondendo a um único processo. Uma coleção de instances com o mesmo propósito, um processo replicado para escalabilidade ou confiabilidade por exemplo, é chamada de job.
Quando o Prometheus faz scrape de um target, ele anexa algumas labels automaticamente às séries temporais scraped que servem para identificar o target scraped:
job- O nome do job configurado ao qual o target pertence.instance- A parte<host>:<port>da URL do target que foi scraped.
Como nossa configuração tem três targets diferentes (com uma instance cada) expondo esta métrica, podemos ver três linhas naquele gráfico.
Monitorando Disponibilidade
Para cada scrape de instance, o Prometheus armazena uma métrica up com o valor 1
quando a instance está saudável, i.e. alcançável, ou 0 se o scrape falhou.
Tente plotar a consulta up na UI do Prometheus.
Se você seguiu todas as instruções até este ponto, notará que até agora todos os targets estavam alcançáveis em todos os momentos.
Vamos mudar isso. Execute docker-compose stop sample-app e depois de alguns
segundos você deve ver a métrica up reportando que nossa aplicação de exemplo
está down.
Agora execute docker-compose restart sample-app e a métrica up deve
reportar que a aplicação está de volta.
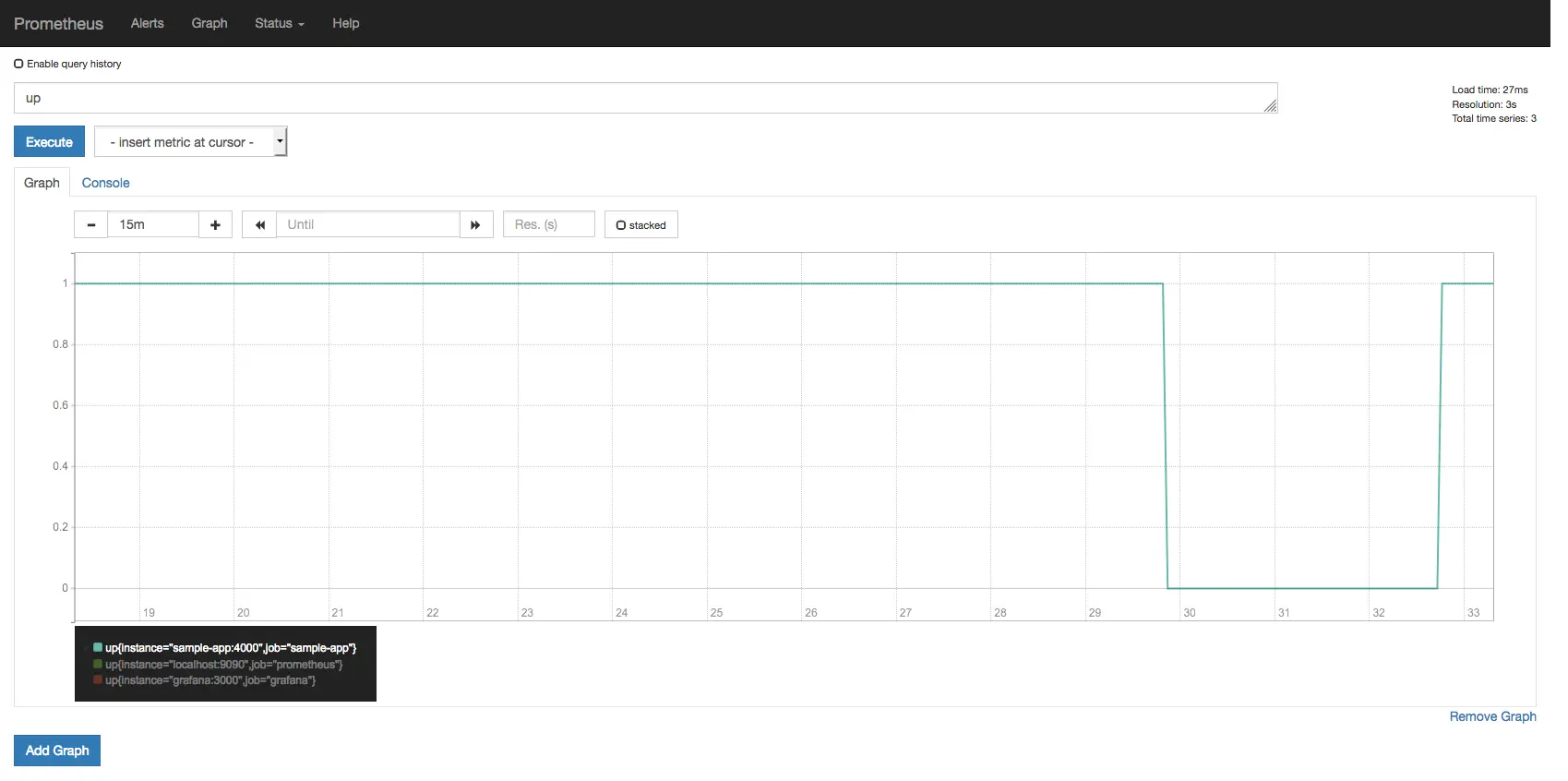
A métrica up mostrando a aplicação de exemplo caindo e voltando.
Quer saber mais? A UI de consulta do Prometheus fornece uma caixa de combinação com todos os nomes de métricas disponíveis registrados em seu banco de dados. Faça algumas explorações, tente consultar diferentes. Por exemplo, você consegue plotar o uso de file descriptor handles (em %) para todos os targets? Dica: os nomes das métricas terminam com
_fds.
Um Alerta Básico de Disponibilidade
Não queremos ficar olhando para dashboards em uma grande TV o dia todo para poder detectar rapidamente problemas em nossas aplicações, afinal, temos coisas melhores para fazer com nosso tempo, certo?
Felizmente, o Prometheus fornece uma facilidade para definir regras de alerta que, quando disparadas, notificarão o Alertmanager, que é o componente que cuida de deduplicar, agrupar e rotear para a integração de receptor correta (i.e. email, Slack, PagerDuty, OpsGenie). Ele também cuida do silenciamento e inibição de alertas.
Configurar o Alertmanager para enviar métricas para PagerDuty, ou Slack, ou o que for, está fora do escopo deste tutorial, mas ainda podemos brincar com alertas.
Já temos a seguinte regra de alerta definida em
config/prometheus/prometheus.rules.yml:
|
|
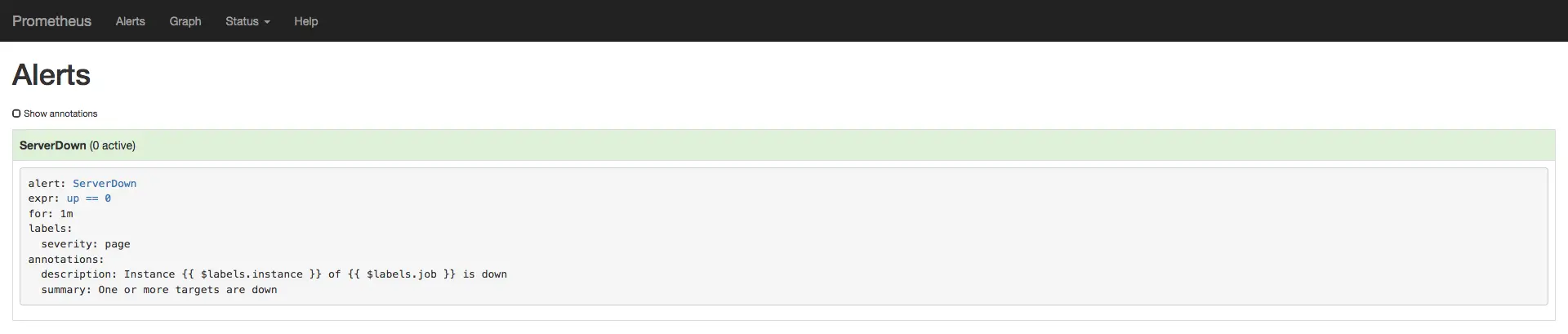
Página de alertas do Prometheus mostrando o alerta ServerDown.
Cada regra de alerta no Prometheus também é uma série temporal, então neste caso você pode
consultar ALERTS{alertname="ServerDown"} para ver o estado daquele alerta em qualquer
ponto no tempo; esta métrica não retornará nenhum ponto de dados agora porque até agora
nenhum alerta foi disparado.
Vamos mudar isso. Execute docker-compose stop grafana para matar o Grafana. Depois de
alguns segundos você deve ver o alerta ServerDown transitar para um estado amarelo,
ou PENDING.
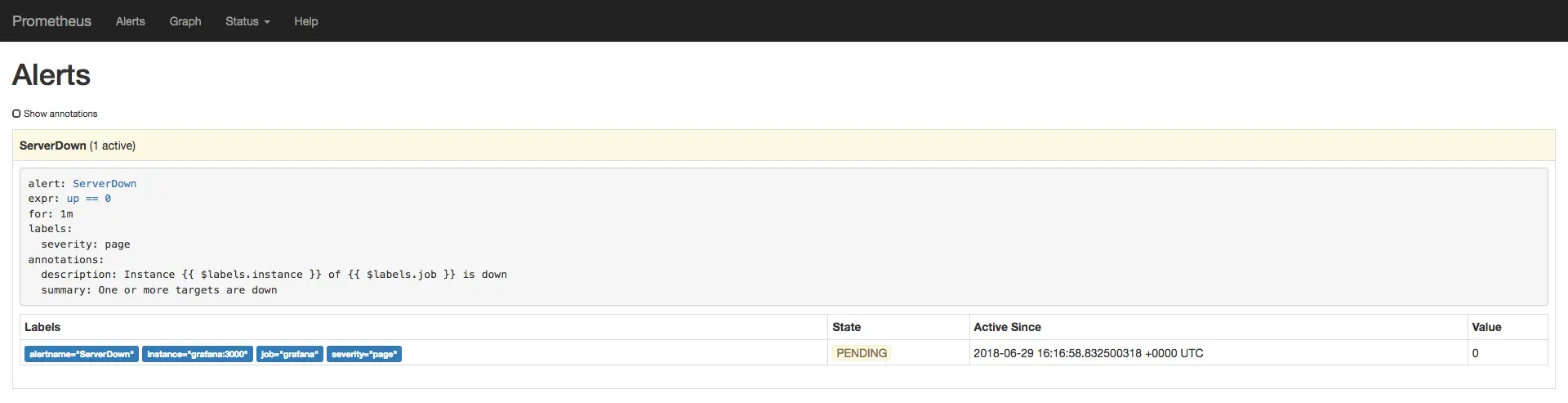
O alerta ServerDown em estado PENDING.
O alerta permanecerá como PENDING por um minuto, que é o limiar que
configuramos em nossa regra de alerta. Depois disso, o alerta transitará para um estado
vermelho, ou FIRING.
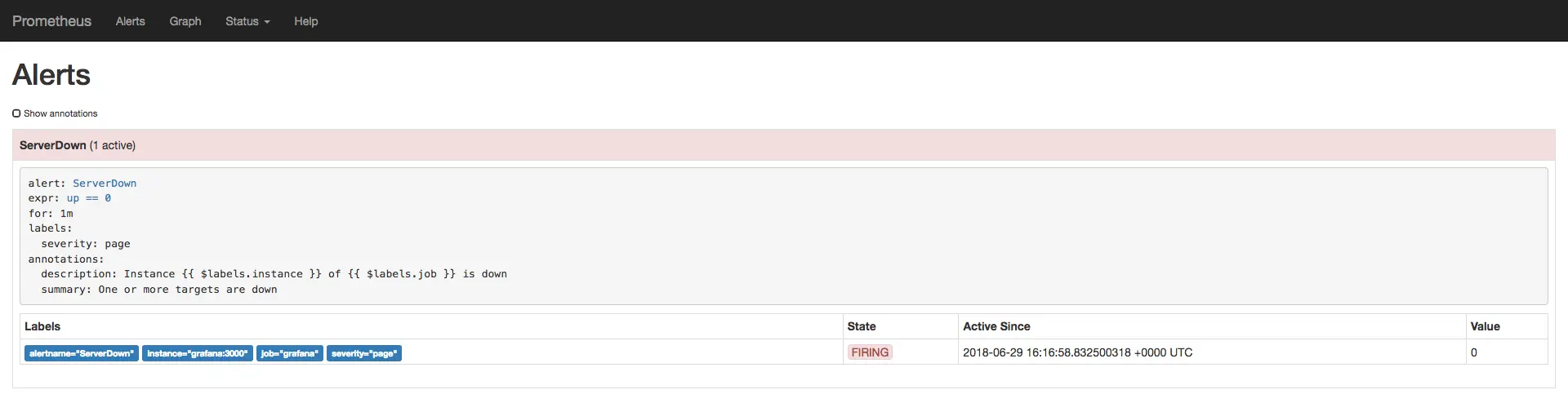
O alerta ServerDown em estado FIRING.
Após esse ponto, o alerta aparecerá no Alertmanager. Visite http://localhost:9093 para abrir a UI do Alertmanager.
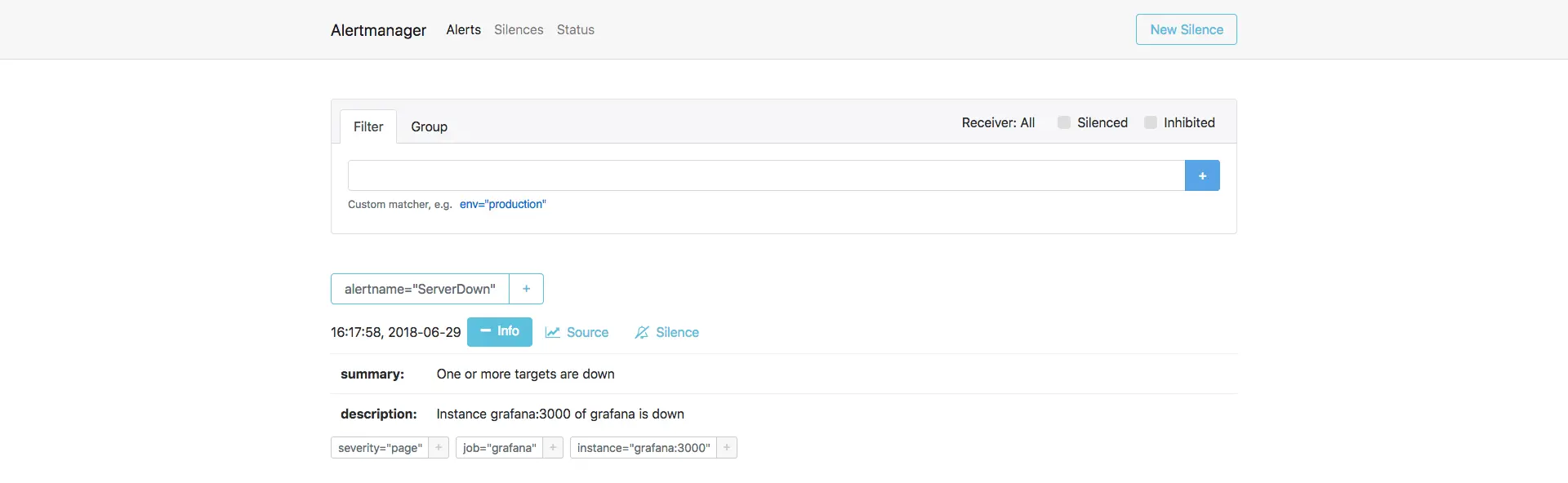
O alerta ServerDown exibido na UI do Alertmanager.
Vamos restaurar o Grafana. Execute docker-compose restart grafana e o alerta
deve voltar a um estado verde após alguns segundos.
Quer saber mais? Há vários exemplos de regras de alerta no repositório awesome-prometheus-alerts para cenários comuns e sistemas populares.
Instrumentando Suas Aplicações
Vamos examinar uma aplicação Node.js de exemplo que criamos para este tutorial.
Abra o arquivo ./sample-app/index.js em seu editor de texto favorito. O
código está totalmente comentado, então você não deve ter dificuldade em entendê-lo.
Medindo Durações de Requisição
Podemos medir durações de requisição com percentis ou médias. Não é recomendado confiar em médias para rastrear durações de requisição porque médias podem ser muito enganosas (veja as Referências para alguns posts sobre as armadilhas das médias e como percentis podem ajudar). Uma maneira melhor de medir durações é via percentis pois rastreia a experiência do usuário mais de perto:
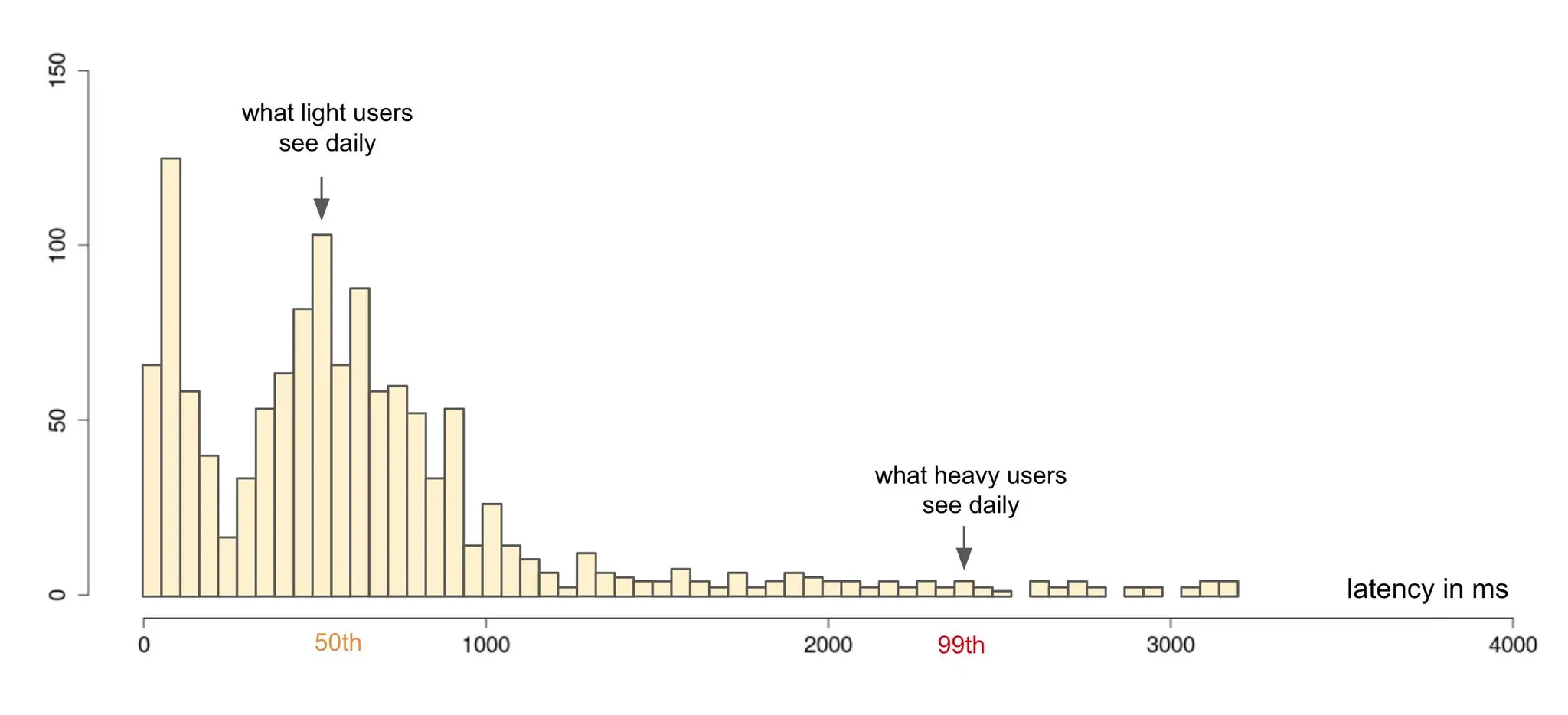
Percentis como forma de medir satisfação do usuário. Fonte: Twitter
No Prometheus, podemos gerar percentis com summaries ou histograms.
Para mostrar as diferenças entre esses dois, nossa aplicação de exemplo expõe duas métricas customizadas para medir durações de requisição, uma via summary e outra via histogram:
|
|
Como você pode ver, em um summary especificamos os percentis nos quais queremos que o cliente Prometheus calcule e reporte latências, enquanto em um histogram especificamos os buckets de duração nos quais as durações observadas serão armazenadas como um contador (i.e. uma observação de 300ms será armazenada incrementando o contador correspondente ao bucket 250ms-500ms).
Nossa aplicação de exemplo introduz um atraso de um segundo em aproximadamente 5% das requisições, só para que possamos comparar o tempo médio de resposta com percentis 99:
|
|
Vamos colocar alguma carga neste servidor para gerar algumas métricas para brincarmos:
|
|
Agora execute as seguintes consultas na UI do Prometheus:
|
|
O resultado dessas consultas pode parecer surpreendente.
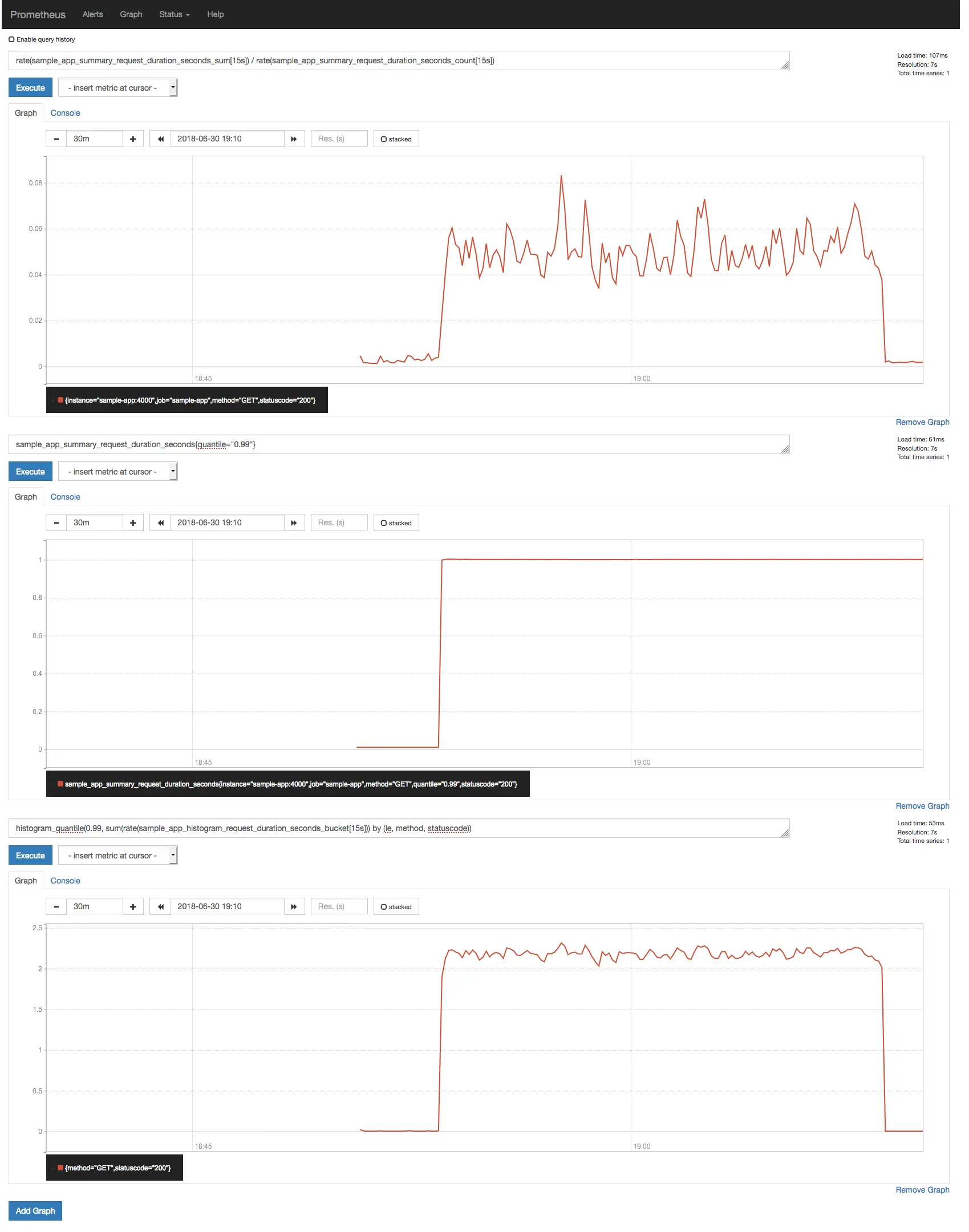
Comparação entre tempo médio de resposta e percentil 99, mostrando diferença significativa.
A primeira coisa a notar é como o tempo médio de resposta falha em
comunicar o comportamento real da distribuição de duração de resposta
(média: 50ms; p99: 1s); a segunda é como o percentil 99 reportado pelo
summary (1s) é bem diferente do estimado pela
função histogram_quantile() (~2.2s). Como pode ser?
Erros de Estimação de Quantil
Citando a documentação:
Você pode usar tanto summaries quanto histograms para calcular os chamados φ-quantis, onde 0 ≤ φ ≤ 1. O φ-quantil é o valor de observação que classifica no número φ*N entre as N observações. Exemplos de φ-quantis: O quantil 0.5 é conhecido como mediana. O quantil 0.95 é o percentil 95.
A diferença essencial entre summaries e histograms é que summaries calculam φ-quantis de streaming no lado do cliente e os expõem diretamente, enquanto histograms expõem contagens de observação em buckets e o cálculo de quantis dos buckets de um histogram acontece no lado do servidor usando a função
histogram_quantile().
Em outras palavras, para que a estimação de quantil dos buckets de um histogram seja precisa, precisamos ter cuidado ao escolher o layout de buckets; se não corresponder ao intervalo e distribuição das durações observadas reais, você obterá quantis imprecisos como resultado.
Lembrando nossa configuração atual de histogram:
|
|
Aqui estamos usando uma configuração de bucket exponencial na qual os buckets dobram de tamanho a cada passo. Este é um padrão amplamente usado; já que sempre esperamos que nossos serviços respondam rapidamente (i.e. com tempo de resposta entre 0 e 300ms), especificamos mais buckets para aquela faixa, e menos buckets para durações de requisição que achamos menos prováveis de ocorrer.
De acordo com o gráfico anterior, todas as requisições lentas da nossa aplicação estão caindo no bucket 1s-2.5s, resultando nesta perda de precisão ao calcular o percentil 99.
Como sabemos que nossa aplicação levará no máximo ~1s para responder, podemos escolher um layout de bucket mais apropriado:
|
|
Vamos iniciar um servidor Prometheus limpo com a configuração de bucket modificada para ver se a estimação de quantil melhora:
|
|
Se você re-executar o teste de carga, agora deve obter algo assim:
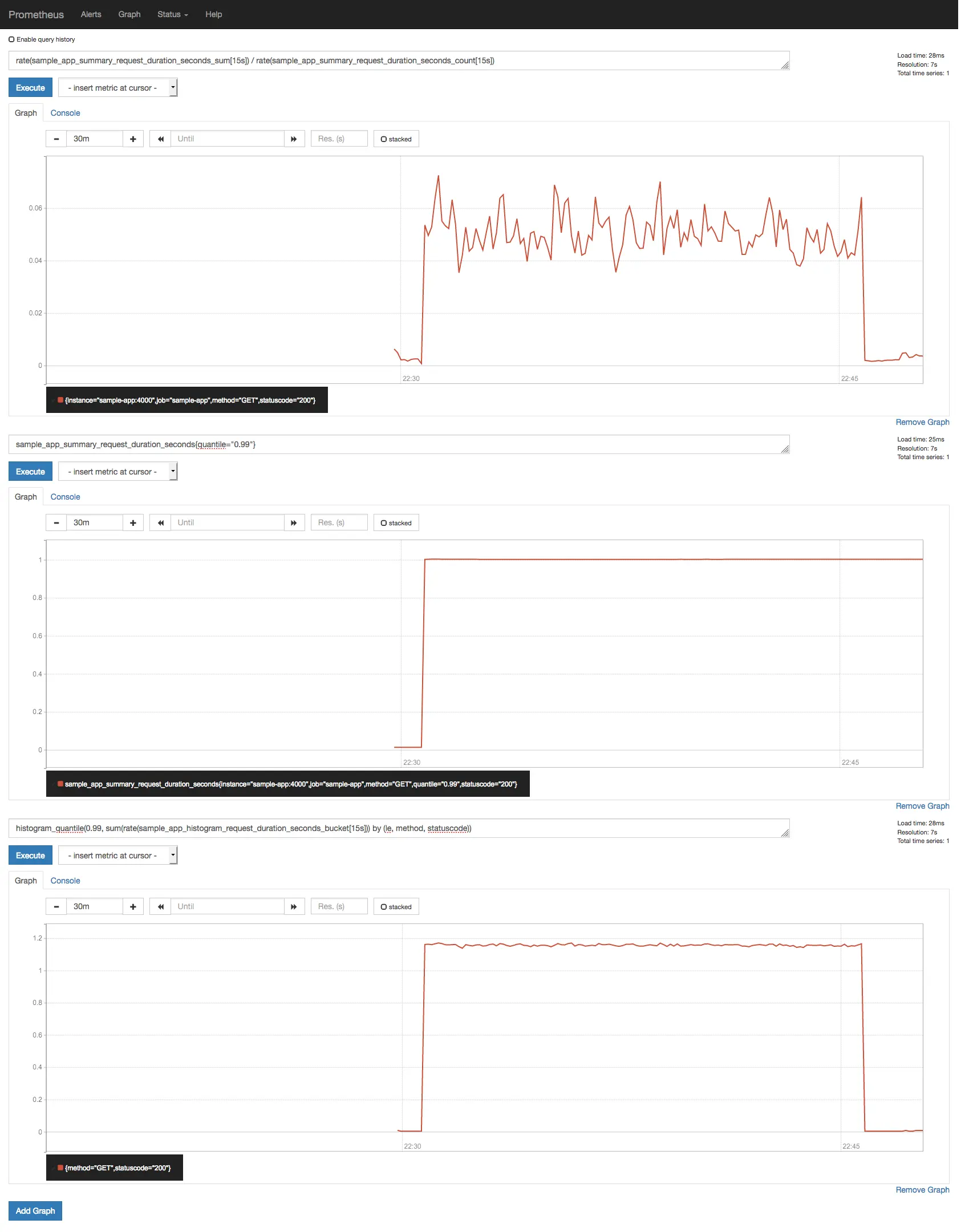
Tempos de resposta com configuração de bucket de histogram melhorada.
Não está exatamente lá, mas é uma melhoria!
Quer saber mais? Se tudo que é necessário para alcançarmos dados de histogram de alta precisão é usar mais buckets, por que não usar um grande número de buckets pequenos?
A razão é eficiência. Lembre-se:
mais buckets == mais séries temporais == mais espaço == consultas mais lentas
Digamos que você tenha um SLO (mais detalhes sobre SLOs depois) para servir 99% das requisições em 300ms. Se tudo que você quer saber é se está honrando seu SLO ou não, não importa realmente se a estimação de quantil não é precisa para requisições mais lentas que 300ms.
Você também pode estar se perguntando: se summaries são mais precisos, por que não usar summaries em vez de histograms?
Citando a documentação:
Um summary não teria tido problema em calcular o valor percentil correto na maioria dos casos. Infelizmente, não podemos usar um summary se precisamos agregar as observações de várias instances.
Histograms são mais versáteis nesse aspecto. Se você tem uma aplicação
com múltiplas réplicas, pode usar com segurança a função histogram_quantile()
para calcular o percentil 99 em todas as requisições para todas as
réplicas. Você não pode fazer isso com summaries. Quer dizer, você pode fazer avg() dos
percentis 99 de todas as réplicas, ou pegar o max(), mas o valor que você
obtém será estatisticamente incorreto e não pode ser usado como proxy para o
percentil 99.
Medindo Throughput
Se você está usando um histogram para medir duração de requisição, pode usar
a série temporal <basename>_count para medir throughput sem ter que
introduzir outra métrica.
Por exemplo, se o nome da sua métrica histogram é
sample_app_histogram_request_duration_seconds, então você pode usar a
métrica sample_app_histogram_request_duration_seconds_count para medir
throughput:
|
|
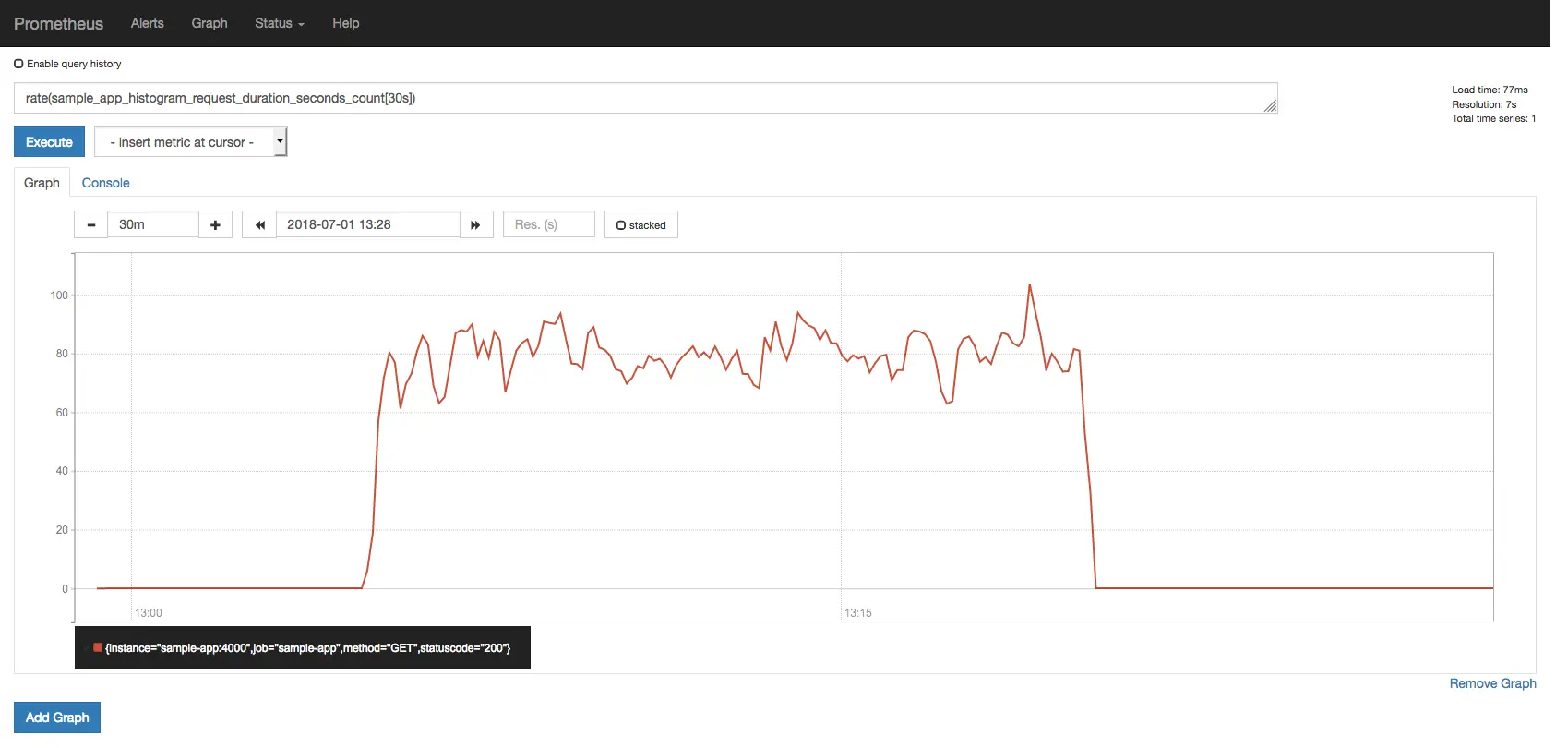
Requisições por segundo medidas usando a métrica count do histogram.
Medindo Uso de Memória/CPU
A maioria dos clientes Prometheus já fornece um conjunto padrão de métricas; prom-client, o cliente Prometheus para Node.js, faz isso também.
Tente essas consultas na UI do Prometheus:
|
|
Se você usar wrk para colocar alguma carga em nossa aplicação de exemplo você pode ver
algo assim:
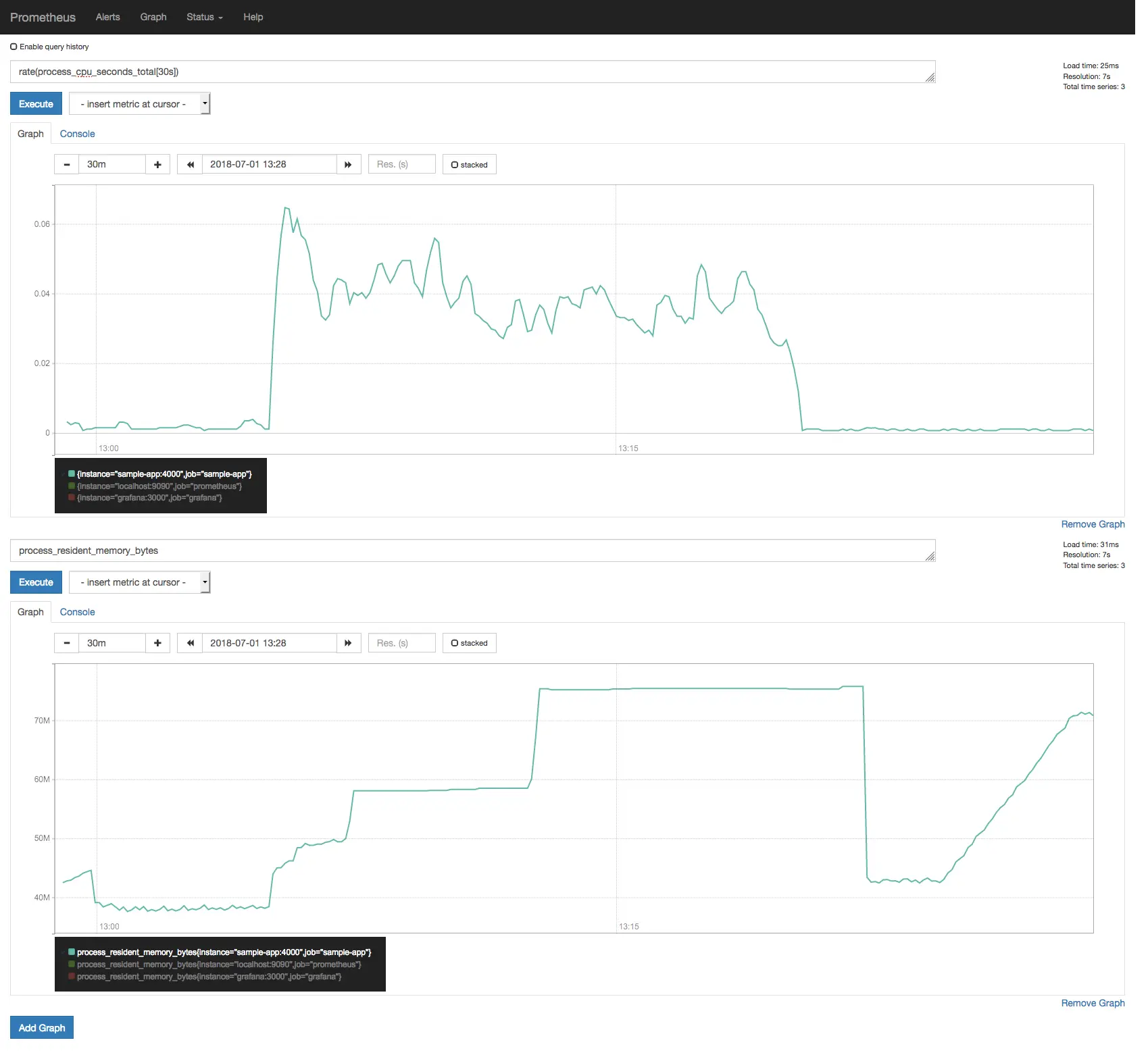
Métricas de uso de memória e CPU da aplicação de exemplo.
Você pode comparar essas métricas com os dados fornecidos por docker stats para ver se
eles concordam entre si.
Quer saber mais? Nossa aplicação de exemplo exporta diferentes métricas para expor algumas informações internas do Node.js, como execuções de GC, uso de heap por tipo, lag do event loop e handles/requisições ativos atuais. Plote essas métricas na UI do Prometheus, e veja como elas se comportam quando você coloca alguma carga na aplicação.
Um dashboard de exemplo contendo todas essas métricas também está disponível no nosso servidor Grafana em http://localhost:3000.
Medindo SLOs e Error Budgets
Gerenciar confiabilidade de serviço é em grande parte sobre gerenciar risco, e gerenciar risco pode ser caro.
100% provavelmente nunca é o alvo de confiabilidade correto: não apenas é impossível de alcançar, é tipicamente mais confiabilidade do que os usuários de um serviço querem ou notam.
SLOs, ou Service Level Objectives, é uma das principais ferramentas empregadas por Site Reliability Engineers (SREs) para tomar decisões baseadas em dados sobre confiabilidade.
SLOs são baseados em SLIs, ou Service Level Indicators, que são as métricas chave que definem quão bem (ou quão mal) um determinado serviço está operando. SLIs comuns seriam o número de requisições falhadas, o número de requisições mais lentas que algum limiar, etc. Embora diferentes tipos de SLOs possam ser úteis para diferentes tipos de sistemas, a maioria dos serviços baseados em HTTP terá SLOs que podem ser classificados em duas categorias: disponibilidade e latência.
Por exemplo, digamos que estes são os SLOs para nossa aplicação de exemplo:
| Categoria | SLI | SLO |
|---|---|---|
| Disponibilidade | A proporção de requisições bem-sucedidas; qualquer status HTTP diferente de 500-599 é considerado bem-sucedido | 95% de requisições bem-sucedidas |
| Latência | A proporção de requisições com duração menor ou igual a 100ms | 95% de requisições abaixo de 100ms |
A diferença entre 100% e o SLO é o que chamamos de Error Budget. Neste exemplo, o error budget para ambos os SLOs é 5%; se a aplicação recebe 1.000 requisições durante a janela de SLO (digamos um minuto para os propósitos deste tutorial), significa que 50 requisições podem falhar e ainda cumpriremos nosso SLO.
Mas precisamos de métricas adicionais para acompanhar esses SLOs? Provavelmente não. Se você está rastreando durações de requisição com um histogram (como estamos aqui), as chances são de que você não precise fazer nada mais. Você já tem todas as métricas de que precisa!
Vamos enviar algumas requisições para o servidor para que possamos brincar com as métricas:
|
|
|
|
Devido ao cenário simulado no qual ~5% das requisições leva 1s para completar, se você tentar a última consulta deve ver que o budget médio disponível é em torno de 0%, isto é, não temos mais budget para gastar e inevitavelmente quebraremos o SLO de latência se mais requisições começarem a levar mais tempo para serem servidas. Este não é um bom lugar para estar.
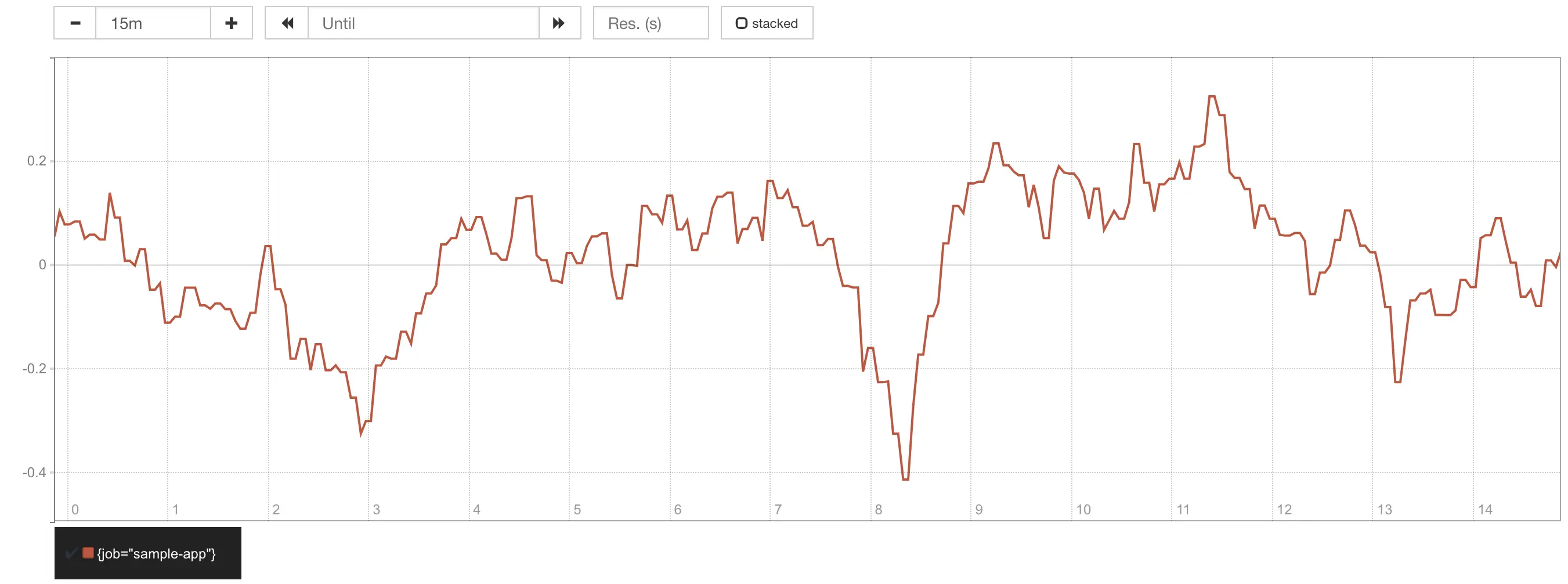
Error budget com SLO de 95% mostrando burn rate de 1x.
Mas e se tivéssemos um SLO mais estrito, digamos, 99% em vez de 95%? Qual seria o impacto dessas requisições lentas no error budget?
Apenas substitua todos os 0.95 por 0.99 naquela consulta para ver o que aconteceria:
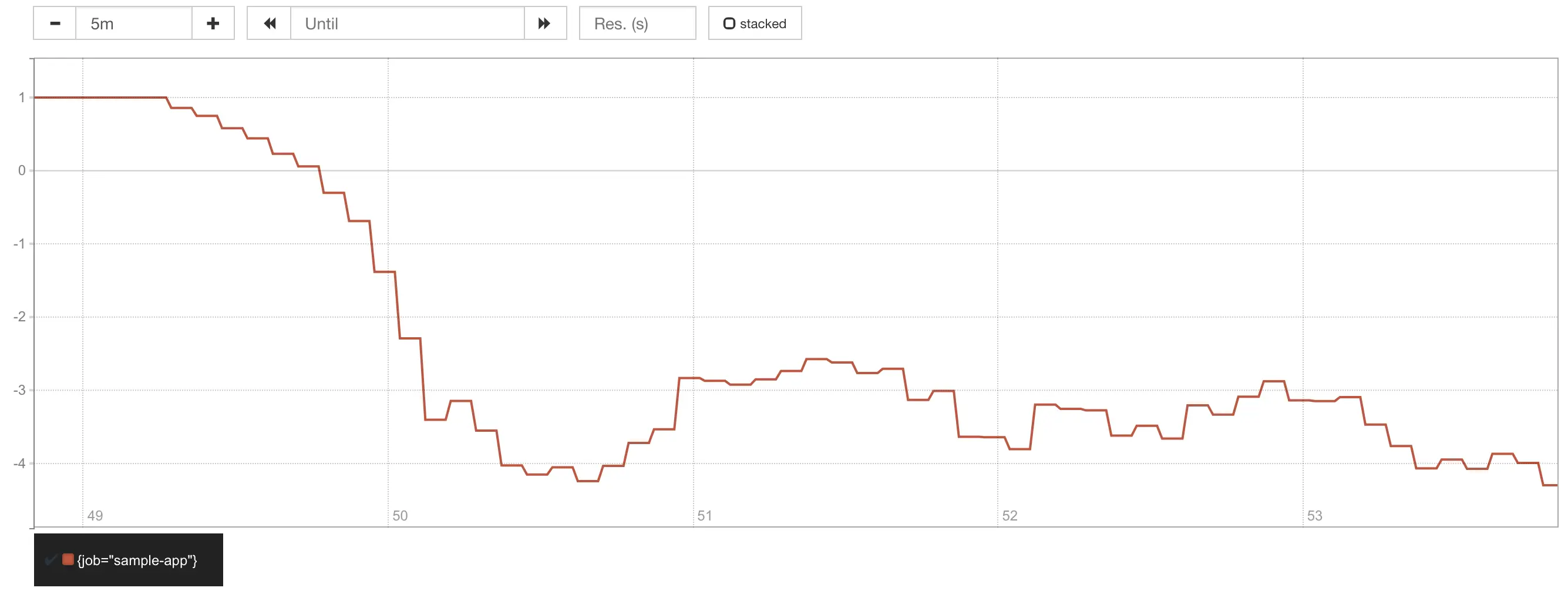
Error budget com SLO de 99% mostrando burn rate de 3x.
No cenário anterior com o SLO de 95%, a burn rate do SLO era ~1x, o que significa que todo o error budget estava sendo consumido durante a janela de SLO, isto é, em 60 segundos. Agora, com o SLO de 99%, a burn rate foi ~3x, o que significa que em vez de levar um minuto para o error budget se esgotar, agora leva apenas ~20 segundos!
Agora mude o curl para apontar para o endpoint /metrics, que não tem
a latência longa simulada para 5% das requisições, e você deve ver o error
budget voltar a 100% novamente:
|
|
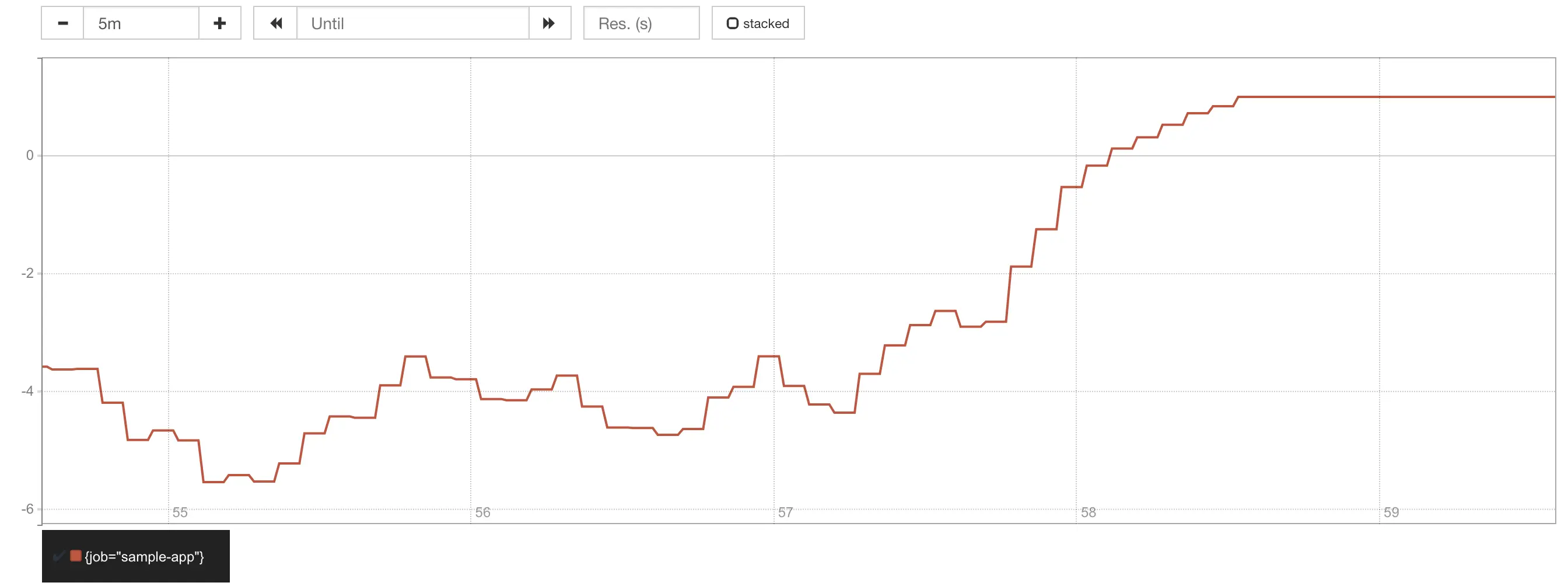
Error budget retornando a 100% após mudar para endpoint rápido.
Quer saber mais? Essas consultas são para calcular o error budget para o SLO de latência medindo o número de requisições mais lentas que 100ms. Agora tente modificar essas consultas para calcular o error budget para o SLO de disponibilidade (requisições com
status=~"5.."), e modifique a aplicação de exemplo para retornar um erro HTTP 5xx para algumas requisições para que você possa validar as consultas.
O Site Reliability Workbook é um ótimo recurso sobre este tópico e inclui conceitos mais avançados como alertar baseado em burn rate de SLO como forma de melhorar precisão/recall de alerta e tempos de detecção/reset.
Monitorando Aplicações Sem um Endpoint de Métricas
Aprendemos que o Prometheus precisa que todas as aplicações exponham um endpoint HTTP
/metrics para que ele faça scrape de métricas. Mas e se você quiser monitorar
uma instância MySQL, que não fornece um endpoint de métricas Prometheus?
O que podemos fazer?
É aí que entram os exporters. A documentação lista uma lista abrangente de exporters oficiais e de terceiros para uma variedade de sistemas, como bancos de dados, sistemas de mensagens, provedores de cloud, e assim por diante.
Para um exemplo muito simplista, confira o projeto aws-limits-exporter que tem cerca de 200 linhas de código Go.
Pegadinhas Finais
A página de documentação do Prometheus sobre instrumentação faz um bom trabalho ao apresentar algumas das coisas para ter cuidado ao instrumentar suas aplicações.
Além disso, esteja ciente de que há convenções sobre o que faz um bom nome de métrica; métricas mal (ou erroneamente) nomeadas lhe causarão dificuldades ao criar consultas depois.
Referências
- Documentação do Prometheus
- Exemplos de consultas Prometheus
- Cliente Prometheus para Node.js
- Keynote: Monitoring, the Prometheus Way (DockerCon 2017)
- Post: Understanding Machine CPU usage
- Post: #LatencyTipOfTheDay: You can’t average percentiles. Period.
- Post: Why Averages Suck and Percentiles are Great
- Livros Site Reliability Engineering