A partir de março de 2026, ingress-nginx não receberá mais novos lançamentos, correções de bugs ou atualizações para resolver quaisquer vulnerabilidades de segurança que possam ser descobertas.
Então você tem um cluster Kubernetes e está usando (ou considerando usar) o controlador de ingress NGINX para encaminhar tráfego externo para serviços dentro do cluster. Isso é incrível!
A primeira vez que olhei para ele, tudo parecia tão fácil; instalar o controlador de
ingress NGINX estava a um helm install de distância, então fiz isso. Depois, após conectar
o DNS ao load balancer e criar alguns
recursos Ingress,
estava em operação.
Avançando alguns meses, todo o tráfego externo para todos os ambientes (dev, staging, produção) estava passando pelos servidores de ingress. Tudo estava bom. Até que não estava mais.
Todos nós sabemos como isso acontece. Primeiro, você fica empolgado com aquela coisa nova e brilhante. Você começa a usar. Então, eventualmente, alguma merda acontece.
Minha Primeira Interrupção de Ingress
Deixe-me começar dizendo que se você não está alertando sobre overflows de fila de accept, bem, você deveria estar.
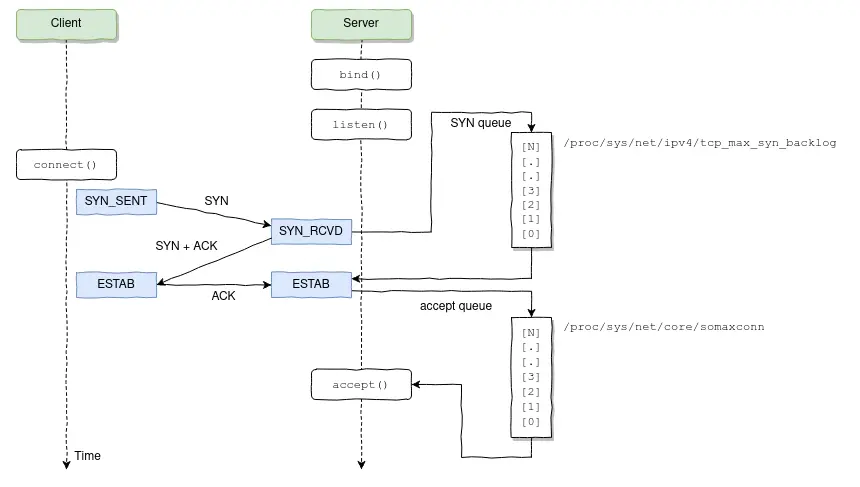
Diagrama de fluxo de conexão TCP.
O que aconteceu foi que uma das aplicações sendo proxiadas através do NGINX começou a demorar muito para responder, fazendo com que as conexões preenchessem completamente o backlog de listen do NGINX, o que fez com que o NGINX rapidamente começasse a descartar conexões, incluindo as que estavam sendo feitas pelas probes de liveness/readiness do Kubernetes.
O que acontece quando algum pod falha em responder às probes de liveness? Kubernetes acha que há algo errado com o pod e o reinicia. O problema é que esta é uma daquelas situações onde reiniciar um pod na verdade fará mais mal do que bem; a fila de accept vai encher demais, de novo e de novo, fazendo com que o Kubernetes continue reiniciando os pods NGINX até que todos comecem a entrar em crash-loop.
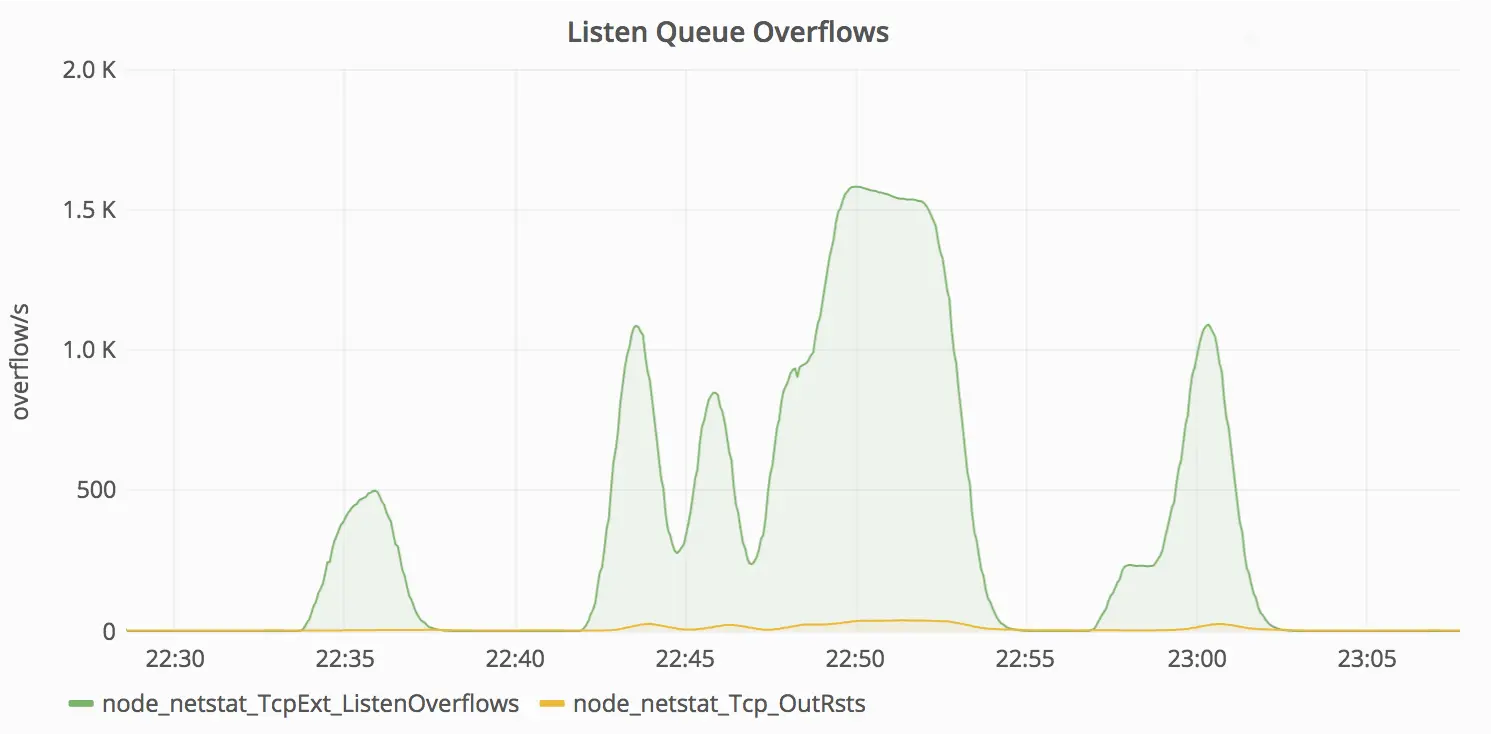
Picos de erros de overflow de listen TCP.
Quais são as lições aprendidas com este incidente?
- Conheça cada pedaço da sua configuração NGINX. Procure por qualquer coisa que deveria (ou não deveria) estar lá, e não confie cegamente em nenhum valor padrão.
- A maioria das distribuições Linux não fornece uma configuração ótima para executar
servidores web de alta carga prontos para uso; verifique novamente os valores para cada parâmetro do
kernel via
sysctl -a. - Certifique-se de medir a latência entre seus serviços e definir os vários timeouts com base no limite superior esperado + alguma folga para acomodar pequenas variações.
- Mude suas aplicações para descartar requisições ou degradar graciosamente quando sobrecarregadas. Por exemplo, em aplicações NodeJS, aumentos de latência no event loop podem indicar que o servidor está com problemas para acompanhar o tráfego atual.
- Não use apenas um deployment de controlador de ingress NGINX para balancear entre todos os tipos de cargas de trabalho/ambientes.
A Importância da Observabilidade
Antes de detalhar cada um dos pontos anteriores, meu conselho nº 0 é nunca executar um cluster Kubernetes de produção (ou qualquer outra coisa) sem monitoramento adequado; por si só, o monitoramento não impedirá que coisas ruins aconteçam, mas coletar dados de telemetria durante tais incidentes lhe dará meios para encontrar a causa raiz e corrigir a maioria dos problemas que você encontrará ao longo do caminho.
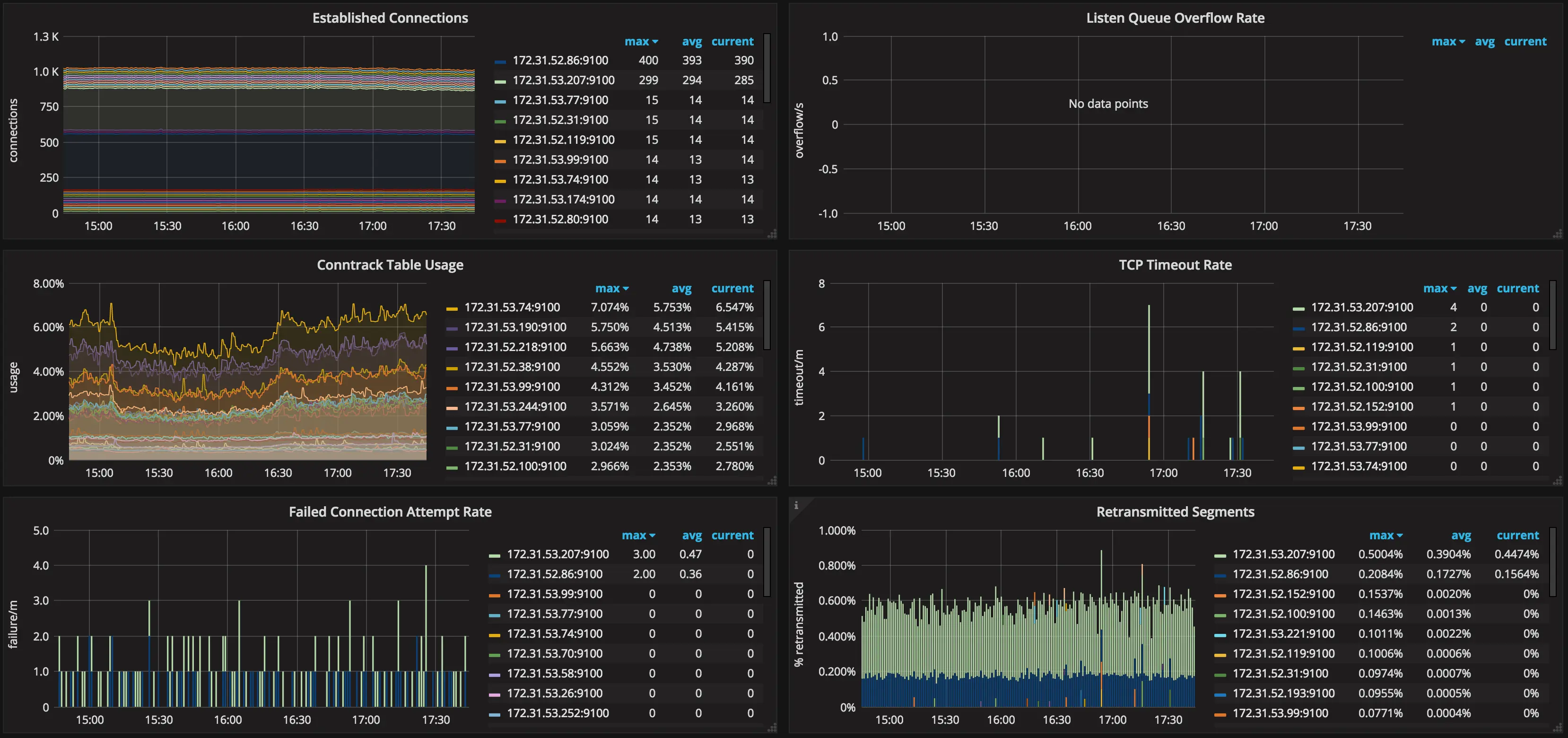
Métricas do Netstat no Grafana.
Se você escolher pular na onda do Prometheus, pode aproveitar o node_exporter para coletar métricas em nível de nó que podem ajudá-lo a detectar situações como a que acabei de descrever.
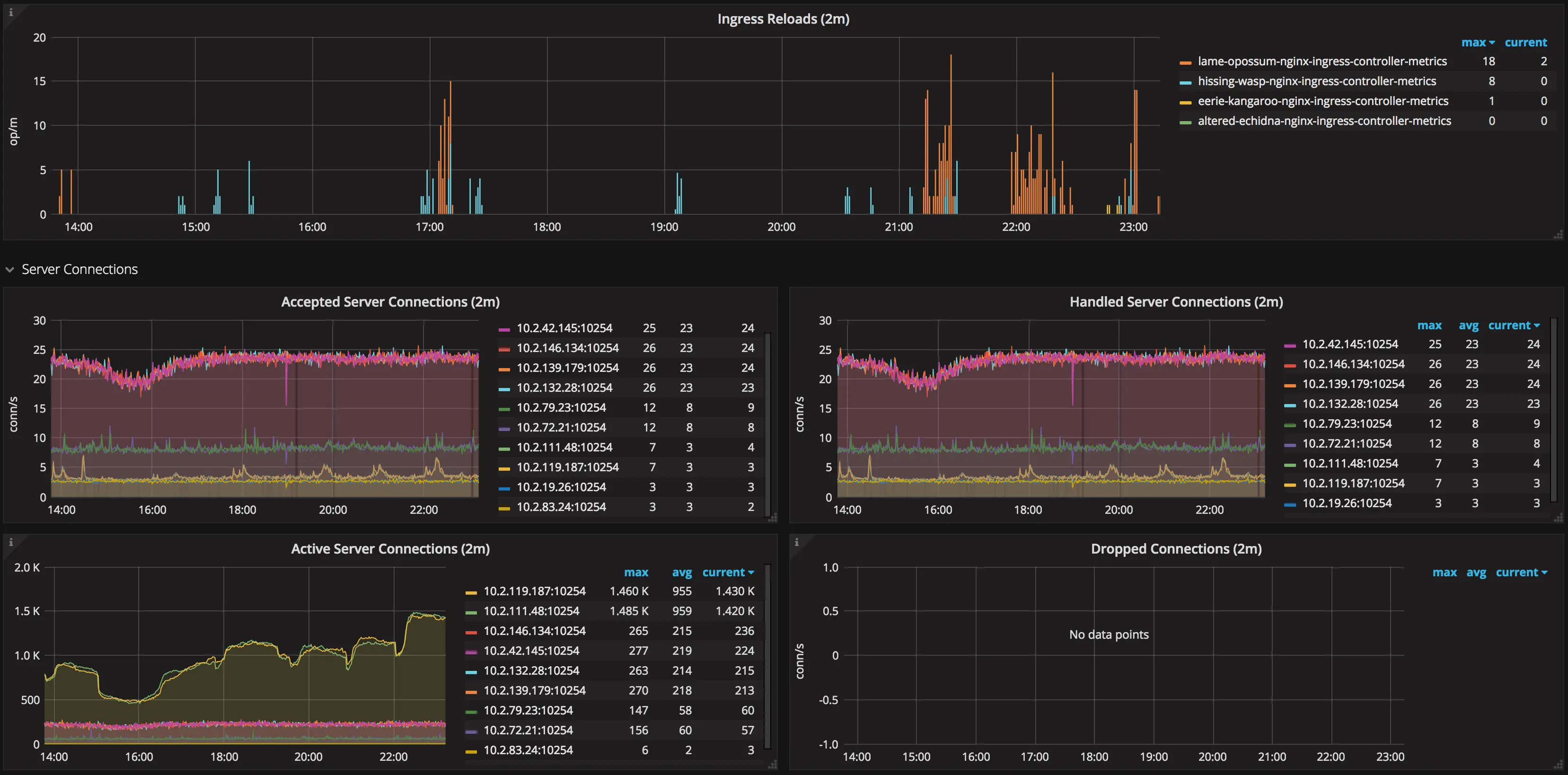
Métricas do controlador de ingress NGINX no Grafana.
Além disso, o próprio controlador de ingress NGINX expõe métricas do Prometheus; certifique-se de coletar essas também.
Conheça Sua Configuração
A beleza dos controladores de ingress é que você delega a tarefa de gerar e recarregar a configuração do proxy para este belo pedaço de software e nunca se preocupa com isso; você nem precisa estar familiarizado com a tecnologia subjacente (NGINX neste caso). Certo? Errado!
Se você ainda não fez isso, eu o encorajo a dar uma olhada na configuração que
seu controlador de ingress gerou para você. Para o controlador de ingress NGINX,
tudo que você precisa fazer é pegar o conteúdo de /etc/nginx/nginx.conf via kubectl.
|
|
Agora procure por qualquer coisa que não seja compatível com sua configuração. Quer um exemplo? Vamos começar com worker_processes auto;
|
|
O valor ótimo depende de muitos fatores incluindo (mas não limitado a) o número de núcleos de CPU, o número de discos rígidos que armazenam dados, e padrão de carga. Quando alguém está em dúvida, defini-lo para o número de núcleos de CPU disponíveis seria um bom começo (o valor “
auto” tentará detectá-lo automaticamente).
Aqui está a primeira pegadinha: até agora (algum dia será?), NGINX não é
Cgroups-aware, o que significa que o valor auto
usará o número de núcleos físicos de CPU na máquina host, não o
número de CPUs “virtuais” como definido pelos
pedidos/limites de recursos do Kubernetes.
Vamos fazer um pequeno experimento. O que acontece quando você tenta carregar o seguinte arquivo de configuração NGINX de um container limitado a apenas uma CPU em um servidor dual-core? Ele gerará um ou dois processos worker?
|
|
Assim, se você pretende restringir o compartilhamento de CPU do ingress NGINX, pode não fazer
sentido gerar um grande número de workers por container. Se esse é o caso, certifique-se
de definir explicitamente o número desejado na diretiva worker_processes.
|
|
Agora pegue a diretiva listen; ela não especifica o parâmetro backlog
(que é 511 por padrão no Linux). Se o net.core.somaxconn do seu kernel está
definido para, digamos, 1024, você também deve especificar o parâmetro backlog=X
adequadamente. Em outras palavras, certifique-se de que sua configuração está em sintonia com seu kernel.
E por favor, não pare por aí. Faça este exercício mental para cada linha da
configuração gerada. Diabos, dê uma olhada em
todas as coisas
que o controlador de ingress permitirá que você mude, e não hesite em
mudar qualquer coisa que não se adeque ao seu caso de uso. A maioria das diretivas NGINX podem ser
customizadas
via entradas de ConfigMap e/ou annotations.
Parâmetros do Kernel
Usando ingress ou não, certifique-se de sempre revisar e ajustar os parâmetros do kernel dos seus nós de acordo com as cargas de trabalho esperadas.
Este é um assunto bastante complexo por si só, então não tenho intenção de cobrir tudo neste post; dê uma olhada na seção Referências para mais orientações nesta área.
Kube-Proxy: Tabela Conntrack
Se você está usando Kubernetes, não preciso explicar o que Services são e para que são usados. No entanto, acho importante entender em mais detalhes como eles funcionam.
Cada nó em um cluster Kubernetes executa um kube-proxy, que é responsável por implementar uma forma de IP virtual para
Servicesde tipo diferente deExternalName. No Kubernetes v1.0 o proxy era puramente em userspace. No Kubernetes v1.1 um proxy iptables foi adicionado, mas não era o modo de operação padrão. Desde o Kubernetes v1.2, o proxy iptables é o padrão.
Em outras palavras, todos os pacotes enviados para um IP de Service são encaminhados/balanceados para
os Endpoints correspondentes (tuplas endereço:porta para todos os pods que correspondem ao
Service
seletor de label)
via regras iptables gerenciadas pelo kube-proxy;
conexões a IPs de Service são rastreadas pelo kernel via o módulo nf_conntrack,
e, como você deve ter imaginado, esta informação de rastreamento de conexão é
armazenada na RAM.
Como os valores de diferentes parâmetros conntrack precisam ser definidos em conformidade uns com
os outros (ie. nf_conntrack_max e nf_conntrack_buckets), kube-proxy
configura padrões sensatos para esses como parte de seu procedimento de inicialização.
$ kubectl -n kube-system logs <some-kube-proxy-pod>
I0829 22:23:43.455969 1 server.go:478] Using iptables Proxier.
I0829 22:23:43.473356 1 server.go:513] Tearing down userspace rules.
I0829 22:23:43.498529 1 conntrack.go:98] Set sysctl 'net/netfilter/nf_conntrack_max' to 524288
I0829 22:23:43.498696 1 conntrack.go:52] Setting nf_conntrack_max to 524288
I0829 22:23:43.499167 1 conntrack.go:83] Setting conntrack hashsize to 131072
I0829 22:23:43.503607 1 conntrack.go:98] Set sysctl 'net/netfilter/nf_conntrack_tcp_timeout_established' to 86400
I0829 22:23:43.503718 1 conntrack.go:98] Set sysctl 'net/netfilter/nf_conntrack_tcp_timeout_close_wait' to 3600
I0829 22:23:43.504052 1 config.go:102] Starting endpoints config controller
...
Estes são bons padrões, mas você pode querer aumentá-los se seus dados de monitoramento mostrarem que você está ficando sem espaço conntrack. No entanto, tenha em mente que aumentar esses parâmetros resultará em aumento do uso de memória, então seja gentil.
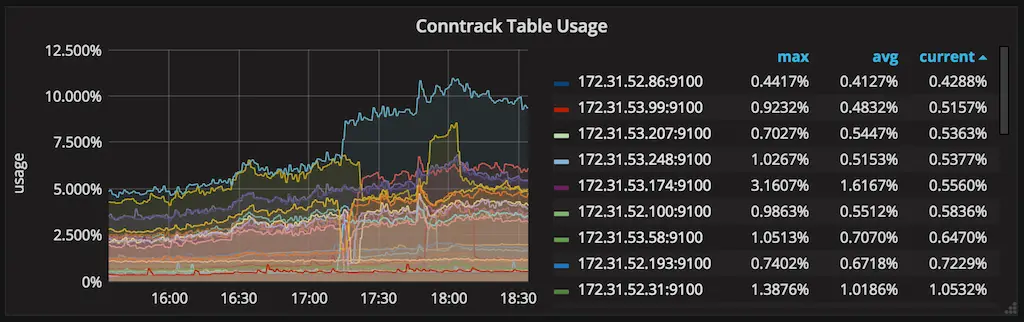
Uso do conntrack.
Compartilhar (Não) é Se Importar
Costumávamos ter apenas um único deployment de ingress NGINX responsável por proxiar requisições para todas as aplicações em todos os ambientes (dev, staging, produção) até recentemente. Posso dizer por experiência que esta é uma má prática; não coloque todos os ovos na mesma cesta.
Acho que o mesmo poderia ser dito sobre compartilhar um cluster para todos os ambientes, mas descobrimos que, ao fazer isso, obtemos melhor utilização de recursos ao permitir que pods de dev/staging rodem em um tier de QoS de best-effort, ocupando recursos não usados por aplicações de produção.
O trade-off é que isso limita as coisas que podemos fazer ao nosso cluster. Por exemplo, se decidirmos executar um teste de carga em um serviço de staging, precisamos ser realmente cuidadosos ou arriscamos afetar serviços de produção rodando no mesmo cluster.
Mesmo que o nível de isolamento fornecido por containers seja geralmente bom, eles ainda dependem de recursos do kernel compartilhados que estão sujeitos a abuso.
Divida Deployments de Ingress Por Ambiente
Dito isso, não há razão para não usar ingresses dedicados por ambiente. Isso lhe dará uma camada extra de proteção caso seus serviços de dev/staging sejam mal utilizados.
Alguns outros benefícios de fazer isso:
- Você tem a chance de usar diferentes configurações para cada ambiente se necessário
- Permitir testar atualizações de ingress em um ambiente mais tolerante antes de lançar em produção
- Evitar inflar a configuração NGINX com muitos upstreams e servidores associados a ambientes efêmeros e/ou instáveis
- Como consequência, seus reloads de configuração serão mais rápidos, e você terá menos eventos de reload de configuração durante o dia (discutiremos depois por que você deve se esforçar para manter o número de reloads no mínimo)
Classes de Ingress ao Resgate
Uma maneira de fazer diferentes controladores de ingress gerenciarem diferentes recursos Ingress
no mesmo cluster é usando um nome de classe de ingress diferente por
deployment de ingress, e então anotar seus recursos Ingress para especificar qual
é responsável por controlá-lo.
|
|
Reloads de Ingress Deram Errado
Neste ponto, já estávamos executando um controlador de ingress dedicado para o ambiente de produção. Tudo estava rodando muito bem até que decidimos migrar uma aplicação WebSocket para Kubernetes + ingress.
Logo após a migração, comecei a notar uma tendência estranha no uso de memória para os pods de ingress de produção.
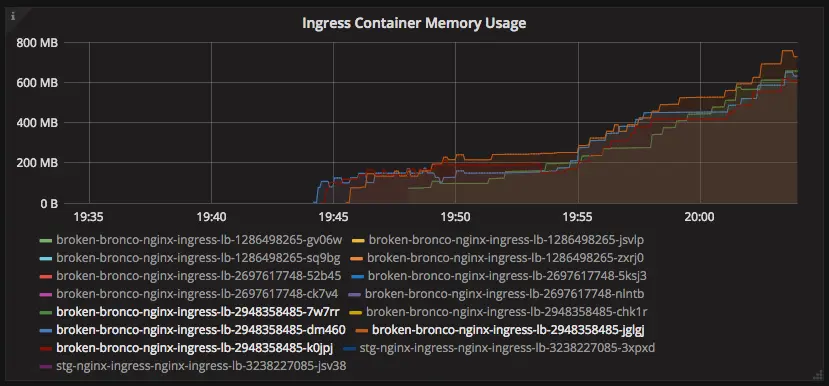
Containers nginx-ingress vazando memória.
Por que o consumo de memória estava disparando assim? Depois que dei kubectl exec em
um dos containers de ingress, o que encontrei foi um monte de processos worker
presos em estado de shutting down por vários minutos.
root 17755 17739 0 19:47 ? 00:00:00 /usr/bin/dumb-init /nginx-ingress-controller --default-backend-service=kube-system/broken-bronco-nginx-ingress-be --configmap=kube-system/broken-bronco-nginx-ingress-conf --ingress-class=nginx-ingress-prd
root 17765 17755 0 19:47 ? 00:00:08 /nginx-ingress-controller --default-backend-service=kube-system/broken-bronco-nginx-ingress-be --configmap=kube-system/broken-bronco-nginx-ingress-conf --ingress-class=nginx-ingress-prd
root 17776 17765 0 19:47 ? 00:00:00 nginx: master process /usr/sbin/nginx -c /etc/nginx/nginx.conf
nobody 18866 17776 0 19:49 ? 00:00:05 nginx: worker process is shutting down
nobody 19466 17776 0 19:51 ? 00:00:01 nginx: worker process is shutting down
nobody 19698 17776 0 19:51 ? 00:00:05 nginx: worker process is shutting down
nobody 20331 17776 0 19:53 ? 00:00:05 nginx: worker process is shutting down
nobody 20947 17776 0 19:54 ? 00:00:03 nginx: worker process is shutting down
nobody 21390 17776 1 19:55 ? 00:00:05 nginx: worker process is shutting down
nobody 22139 17776 0 19:57 ? 00:00:00 nginx: worker process is shutting down
nobody 22251 17776 0 19:57 ? 00:00:01 nginx: worker process is shutting down
nobody 22510 17776 0 19:58 ? 00:00:01 nginx: worker process is shutting down
nobody 22759 17776 0 19:58 ? 00:00:01 nginx: worker process is shutting down
nobody 23038 17776 1 19:59 ? 00:00:03 nginx: worker process is shutting down
nobody 23476 17776 1 20:00 ? 00:00:01 nginx: worker process is shutting down
nobody 23738 17776 1 20:00 ? 00:00:01 nginx: worker process is shutting down
nobody 24026 17776 2 20:01 ? 00:00:02 nginx: worker process is shutting down
nobody 24408 17776 4 20:01 ? 00:00:01 nginx: worker process
Para entender por que isso aconteceu, devemos dar um passo atrás e olhar como o reload de configuração é implementado no NGINX.
Uma vez que o processo mestre recebe o sinal para recarregar a configuração, ele verifica a validade da sintaxe do novo arquivo de configuração e tenta aplicar a configuração fornecida nele. Se isso for bem-sucedido, o processo mestre inicia novos processos worker e envia mensagens aos processos worker antigos, solicitando que eles sejam encerrados. Caso contrário, o processo mestre reverte as alterações e continua a trabalhar com a configuração antiga. Processos worker antigos, recebendo um comando para encerrar, param de aceitar novas conexões e continuam a atender requisições atuais até que todas essas requisições sejam atendidas. Depois disso, os processos worker antigos saem.
Lembre-se de que estamos proxiando conexões WebSocket, que são de longa duração por natureza; uma conexão WebSocket pode levar horas, ou até dias para fechar dependendo da aplicação. O servidor NGINX não pode saber se é ok interromper uma conexão durante um reload, então cabe a você facilitar as coisas para ele. (Uma coisa que você pode fazer é ter uma estratégia em vigor para fechar ativamente conexões que estão ociosas por muito tempo, tanto no lado do cliente quanto do servidor; não deixe isso como uma reflexão tardia)
Agora de volta ao nosso problema. Se temos tantos workers nesse estado, isso significa que a configuração do ingress foi recarregada muitas vezes, e os workers não conseguiram terminar devido às conexões de longa duração.
Foi de fato o que aconteceu. Após alguma depuração, descobrimos que o controlador de ingress NGINX estava repetidamente gerando um arquivo de configuração diferente devido a mudanças na ordenação de upstreams e IPs de servidor.
|
|
Isso fez com que o controlador de ingress NGINX recarregasse sua configuração várias
vezes por minuto, fazendo com que esses workers em shutting down se acumulassem até que o pod fosse
OOMKilled.
As coisas melhoraram muito depois que atualizei o controlador de ingress NGINX para uma
versão corrigida e especifiquei a flag de linha de comando --sort-backends=true.
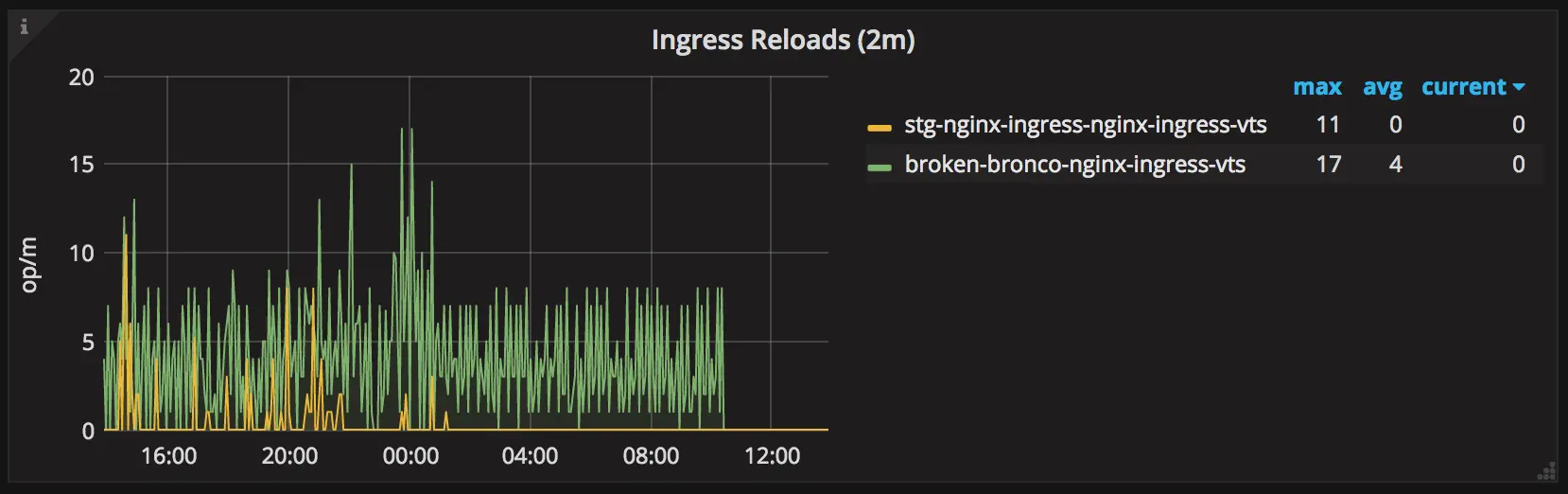
Número de reloads de configuração do nginx-ingress.
Obrigado ao @aledbf por sua assistência em encontrar e corrigir este bug!
Minimizando Ainda Mais os Reloads de Configuração
A lição aqui é ter em mente que reloads de configuração são operações caras e é uma boa ideia evitá-los especialmente ao proxiar conexões WebSocket. É por isso que decidimos criar um deployment de controlador de ingress específico apenas para proxiar essas conexões de longa duração.
No nosso caso, mudanças em aplicações WebSocket acontecem com muito menos frequência do que outras aplicações; ao usar um controlador de ingress separado, evitamos recarregar a configuração para o ingress WebSocket sempre que há mudanças (ou eventos de escalonamento/reinicializações) em outras aplicações.
Separar o deployment também nos deu a habilidade de usar uma configuração de ingress diferente que é mais adequada para conexões de longa duração.
Ajuste Fino de Autoscalers de Pod
Como o ingress NGINX usa IPs de pod como servidores upstream, toda vez que a lista de
endpoints para um dado Service muda, a configuração de ingress deve ser
regenerada e recarregada. Assim, se você está observando eventos frequentes de autoscaling
para suas aplicações durante carga normal, pode ser um sinal de que seus
HorizontalPodAutoscalers precisam de ajuste.
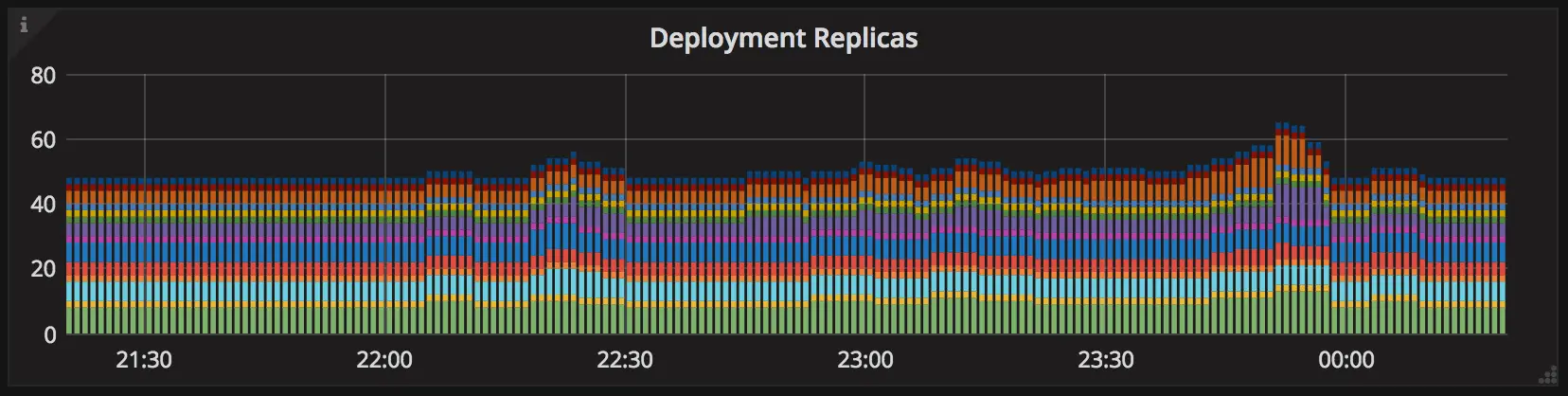
Autoscaler do Kubernetes em ação.
Outra coisa que a maioria das pessoas não percebe é que o autoscaler horizontal de pods tem um timer de back-off que impede que o mesmo alvo seja escalado várias vezes em um curto período.
|
|
De acordo com o valor padrão para a flag --horizontal-pod-autoscaler-upscale-delay
no
kube-controller-manager,
se sua aplicação escalou para cima, ela não poderá escalar para cima novamente por 3 minutos.
Assim, caso sua aplicação realmente experimente uma carga aumentada, pode levar ~4 minutos (3m do back-off do autoscaler + ~1m da sincronização de métricas) para o autoscaler reagir à carga aumentada, o que pode ser tempo suficiente para seu serviço degradar.